技術者ブログ
クラウド型WAF「Scutum(スキュータム)」の開発者/エンジニアによるブログです。
金床“Kanatoko”をはじめとする株式会社ビットフォレストの技術チームが、“WAFを支える技術”をテーマに幅広く、不定期に更新中!
時系列ビッグデータを手軽に可視化するHadoopアプリケーション、Dunkhead
Dunkheadとは
Dunkheadはタイムスタンプ付きのテキストデータ(アクセスログなど)を手軽に可視化するためのソフトウェアです。Hadoop上で動作するMapReduceアプリケーションであるため、データのサイズが大きい、いわゆるビッグデータの場合にも使用することができます。
Dunkheadは、入力データとなるログをもとに、サーバ監視ツールなどで見られるような、横軸が時間、縦軸が目的の値となる画像を出力します。下記の例はNASAのスペースシャトル、ディスカバリー号のミッションの際に記録された、NASAのウェブサーバのアクセスログをDunkheadで可視化したものです(こちらについて、詳しくは『HadoopとDunkheadでNASAのウェブサーバのアクセスログを解析・可視化する』を参照ください)。
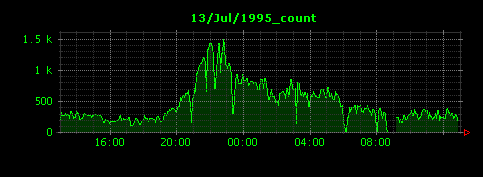
各種サーバのアクセスログなどは、特に活用することなく、いつのまにか大量に溜まってしまうことがあります。後から何か情報を抽出しようと考えても、サイズが大きすぎたり、そもそもどんな情報を取り出せばよいかわからないという問題に直面します。Dunkheadはこの問題を解決するために開発されました。
具体例
Dunkheadを実際に使用するとどんな感じなのか、いくつかの具体例についてのエントリがこちらになります。
- NASAのウェブサーバのアクセスログを解析・可視化
- CodeRedワームの感染の様子の可視化
- JavaアプリケーションのGC(ガベージコレクション)の様子を可視化
- ハッカーの電脳模擬戦(Defcon 8 CTF)のポートスキャンの様子を可視化
- top、vmstatの出力からLinuxシステムの負荷状況を可視化
ビッグデータをまず簡単に可視化して、より深い解析へのヒントを得るために使う
Dunkheadは、ビッグデータ解析の初日に使うことを想定して開発されたソフトウェアです。目の前に大きなデータがあり、それを何かに活かしたい場合、目的がはっきりしているのであれば、必ずしもDunkheadは必要ありません。自分が行いたい解析を具体的に実行するソフトウェアや処理を実装するのがよいでしょう。
しかし「いったいこのデータから何がわかるのか?」と途方に暮れるような状態ならば、まずはDunkheadで可視化を行ってみるというアプローチがおすすめです。時系列でレコード件数や注目する値についての大まかな傾向がわかるので、そこからさらにどのように深く解析していくか、方向を決めるためのヒントを得ることができます。Dunkheadは「最終的に何を得ることにするか」を決める手助けをするツールであり、Dunkheadだけでデータの解析が完了することは基本的には多くありません。
かつてはこのような役割は単にエディタやgrep等のツールが担ってきました。しかしログファイルの行数が100万や1000万、時には億という単位になってくると、これらのアプローチは通用しなくなります。データ全体のざっくりとした傾向を掴むためには、可視化が有効な手段となります。
ダウンロード
http://www.jumperz.net/tools/dunkhead.jarソースコードはGitHubで公開中です。
使い方
DunkheadはJavaで作成されたHadoop用のMap/Reduceアプリケーションなので、使用するにはHadoopが必要となります。動作確認はHadoop-1.0.3およびHadoop-0.23.9で行っています。前項のリンクからダウンロードできるjarファイルではMainクラスが明示されているので、hadoopコマンドのjarオプションを使って起動します。
多くのHadoopアプリケーションと同様に、スタンドアロンモードでも、他の分散モードでも使用できます。
起動のためにはDunkhead用に引数が3つ必要で、それぞれinput-path、output-path、conf-pathとなります。
input-path
input-pathは入力データが置かれているパス(ディレクトリ)になります。サブディレクトリが含まれている場合には再帰的にファイルを見つけ、すべて入力として使用します。Amazon Elastic MapReduceを使う場合には、s3n://で始まるS3のパスが使用できます(output-pathも同様)。
output-path
output-pathは画像が出力されるパスになります。WordCount等のHadoopのサンプルアプリケーションと同様に、実行前にこのパスが存在している場合はエラーとなりますのでご注意ください。
conf-path
conf-pathは設定ファイルのパスです。こちらはディレクトリではなく、設定ファイル名を明示的に指定する必要があります。
例として、カレントディレクトリがHadoopをインストールしたディレクトリであり、入力データが/hadoop/nasa/、出力先が/tmp/output/、そして設定ファイルがカレントディレクトリにdunkhead.confという名前で置いてある場合には、次のようなコマンドで起動します。
bin/hadoop jar dunkhead.jar /hadoop/nasa/ /tmp/output/ dunkhead.conf
設定ファイルの記述について
設定ファイルはJSON形式で記述します。例えば次のようになります。
{
"datetime": {
"format": " [dd/MMM/yyyy:HH:mm:ss Z] ",
"regex": " \\[.{26}\\] "
},
"fields": [
{
"name": "HTTP-Response-Size",
"regex": " ([0-9]+)$",
"type": "average"
}
]
}
上記設定ファイルはこちらで使用されています。
設定ファイルの記述内容は解析対象のデータの内容によって大きく変わります。いくつかの具体例のエントリ内で、それぞれのデータに合わせた設定ファイルの記述方法を詳しく紹介しているので、イメージが掴みづらい場合はそちらも合わせて参照ください。以下では、各項目について説明します。
datetime
タイムスタンプ部に関する設定を記述します。子要素としてformatとregexが存在します。
(datetime)format
データ中のタイムスタンプ部がどのようなフォーマットで表現されているかを記述する項目です。記述方法はこちらのJavaのSimpleDateFormatクラスでの定義に従います。
(datetime)regex
データの各行において、タイムスタンプ部(上記datetime.formatに該当する箇所)をマッチングさせるための正規表現を記述します。()によってグループ化を行う場合には、グループ部分がdatetime.formatとして解釈されます。正規表現の実装はJavaを使用しており、細かい定義についてはJavaのPatternクラスでの定義に従います。
fields
可視化対象とする値について記述する項目です。配列である必要があります。複数指定可能です。配列に含まれる各要素はそれぞれname、regex、type、eval項目を持ちます。(evalのみオプション)
(fields)name
出力される画像に印字される文字列であり、Map/Reduce処理の際のキーの一部としても使われます。regex項目の内容(正規表現)がグループを含む場合、$1や$2のような表現が使用できます(具体例はこちら)。
(fields)regex
可視化したいデータに対するマッチングを行うための正規表現を記述します。
type項目の値がcountの場合は、正規表現にマッチする単位時間あたりの行数がグラフの縦軸として可視化されます(もっとも基本的な、わかりやすいパターンです。具体例はこちら)。
この項目の値となる正規表現では必ずしもグループ化を行う必要はありませんが、name内で$1のような表記を使いたい場合にはグループ化を行います(具体例はこちら)。
type項目の値がaverage、max、minのいずれかの場合は、正規表現で数値部分を取得するようにグループ化する必要があります(具体例はこちら)。基本的には1つめのグループ($1)の値がグラフの縦軸の値として使用されます。$1以外の値を使いたい場合や、100倍するなどの計算処理を行いたい場合は、eval項目で明示的に指定します(具体例はこちら)。
(fields)type
count、average、max、minいずれかの値を指定します。
countの場合は、regex項目の正規表現にマッチする行数が可視化されます。
averageの場合は、regex項目でグループ化した部分の数値について、単位時間ごとの平均値がグラフの縦軸の値となります。
maxの場合は、regex項目でグループ化した部分の数値について、単位時間内での最大値がグラフの縦軸の値となります。
minの場合は、regex項目でグループ化した部分の数値について、単位時間内での最小値がグラフの縦軸の値となります。
(fields)eval
オプションとなる項目であり、必ずしも指定する必要はありません。この項目はtype項目の値がaverage、max、minのいずれかの場合にのみ使用できます。このeval項目が存在しない場合、可視化の対象となる値はregex項目の正規表現の1つめのグループ($1)となりますが、eval項目を使うことで、$2や$3を使ったり、計算を行ったりすることができます。以下に例を示します。
eval項目が『$2』の場合、regex項目の正規表現の2つめのグループ部分の値が可視化対象として扱われます。$3、あるいは$4のような場合も同様です。
eval項目が『$2 - $3』の場合、regex項目の正規表現の2つめのグループ部分の値と3つめのグループ部分の値の差が可視化対象として扱われます。
eval項目が『$1 * 100』の場合、regex項目の正規表現の1つめのグループの値の100倍の値が可視化の対象として扱われます。
この項目の値は実行時にJavaコードとしてコンパイルされて解釈されるため、加算や減算等はJavaの文法に従う形で記述すれば、複雑な記述(『($1 - $2) * $3』など)を行うことも可能です。
rrd
オプションとなる項目です。内部で使用しているRRD(ラウンドロビンデータベース)に関連するパラメータについて、デフォルト値を変更したい場合に使用します。子要素としてstepとheartbeatが存在します。詳しくはこちらを参照してください。また、具体例はこちらを参照ください。
(rrd)step
RRDのstep値です。デフォルトは300秒です。
(rrd)heartbeat
RRDのheartbeat値です。デフォルトは600秒です。
threshold
オプションとなる項目です。出力される画像ファイルの数が大量になることを防ぐために設ける閾値です。該当するレコード数の下限を指定します。具体例はこちらを参照ください。
combiner.inmemory
オプションとなる項目です。Combinerの処理をメモリ上で行いたい場合に、以下のように指定します。
"combiner.inmemory" : true
Map処理に続いて行われるCombinerの処理において、データ量が多すぎない場合には、上記のようにすることでパフォーマンスが向上する可能性があります。Hadoopを稼働させるホストのメモリ量に余裕がある場合に向いてます。メモリが足りない場合にはOutOfMemoryで処理が失敗することもあります。
入力データとして使用可能なフォーマット
入力データとして使用できるのは、各行が独立しており、それぞれの行にタイムスタンプが付加されているテキストファイルです。ただし、データ中に、タイムスタンプ無しの行がいくつか混ざっていても、それらは単に無視されるので問題ありません。
タイムスタンプ部分の形式は、一般的なものであれば使用可能です。タイムスタンプ部をどう解釈するかは設定ファイル中で明示的に指定する必要があります。詳しくは具体的なエントリを参照ください。
Hadoopアプリケーションであること
DunkheadはHadoop上で稼働するアプリケーションです。最も基本的なMap/Reduceアプリケーションであり、Hadoop以外の依存性がありません。そのため、Amazon Elastic MapReduceをはじめとするSaaS型のHadoopサービスであれば、ほぼ間違いなく利用することができます。また、自前のHadoopクラスタを利用できる環境であれば、Dunkheadはその上で、そのまま使うことができるでしょう。
いわゆるビッグデータとよばれる、スケールアウトすることなしには処理できない規模のデータを前提としていますが、当然小さなデータについても可視化することが可能です。データが小さい場合には、Hadoopをスタンドアロンモードで稼働させることで、特にクラスタ等を用意することなく手軽に可視化することができます。
シンプルさの追求
Dunkheadはシンプルさを重視しています。できることは時系列のグラフを描くことだけです。また、ひとつのグラフには一種類のデータ項目しか描画できません。機能をシンプルに保ち、一般的なエンジニアの方であれば、grepやegrepのような感覚で簡単に使えるような方向を目指しています。JSON形式の設定ファイルの記述も簡単で、新しいDSLやクエリ言語のようなものを覚える必要はありません。少し凝りたい部分がある場合は、正規表現を工夫したり、eval項目に計算式を入力することで対応が可能です。
RRD(ラウンドロビンデータベース)を内部で使用
Dunkheadの内部では、MRTGやRRDToolsで知られる、ラウンドロビンデータベースと呼ばれる技術を使っています。実装はJavaによるRRDTools互換のライブラリであるJRobinです。ラウンドロビンデータベースは過去のデータをどんどん圧縮していくため、ビッグデータの処理と非常に相性がよいです。
H2(Java組み込みのRDBMS)を内部で使用
DunkheadはCombinerとReducerにおいて、Java組み込みのRDBMSであるH2を使用しています。H2はHadoop上でRDBMSをスケールアウトさせるために非常に有効な手段です。H2とHadoopの関係について、詳しくはこちらをご覧ください。
Scutumでの活用について
私たちが提供するSaaS型のWAFサービス、Scutum(スキュータム)では、Amazon Elastic MapReduceでDunkheadを用い、22億行、58GB(gzip展開後は約580GB)のアクセスログを2時間弱で可視化しました。今後、現在よりさらに多くのデータを収集し、Dunkheadで可視化を行いつつ、サービスにフィードバックするサイクルを回していこうと考えています。
フィードバック等について
Dunkheadに関するご意見・ご感想などは、お気軽に金床@kinyukaまでお寄せください。