技術者ブログ
クラウド型WAF「Scutum(スキュータム)」の開発者/エンジニアによるブログです。
金床“Kanatoko”をはじめとする株式会社ビットフォレストの技術チームが、“WAFを支える技術”をテーマに幅広く、不定期に更新中!
HadoopとDunkheadでJavaアプリケーションのGC(ガベージコレクション)を可視化する

はじめに
Dunkheadはタイムスタンプ付きのテキストデータ(アクセスログなど)を手軽に可視化するためのソフトウェアです。Hadoop上で動作するため、データのサイズが大きい、いわゆるビッグデータの場合にも使用することができます。
今回は、JavaアプリケーションのメモリのGC(ガベージコレクション)のログを対象に、Dunkheadによる可視化の例を見ていきます。
GCログのフォーマット
私たちの提供するSaaS型WAFサービス、Scutum(スキュータム)の中心となるソフトウェアは、すべてJavaで書かれています。HTTPのプロキシサーバとして長時間休み無く動作するサーバアプリケーションであるため、GCの様子はサービスレベルを適切に保つ上で重要な要素のひとつとなっています。
Javaアプリケーションはデフォルトの状態ではGCのログを出力せず、ログを取得するには起動時に-verbose:gcなどのオプションを渡す必要があります。Scutumでは全サーバにおいてこのオプションを明示的に指定してGCのログを採っており、その際、独自のロガーでタイムスタンプを付加しています。このため、GCログの内容は以下のようになっています。
Tue Jul 30 07:49:39 JST 2013 [GC 1346804K->683119K(1344768K), 0.0071550 secs] Tue Jul 30 07:49:42 JST 2013 [GC 1325039K->691157K(1328384K), 0.0100160 secs] Tue Jul 30 07:49:50 JST 2013 [GC 1310293K->693859K(1303296K), 0.0082060 secs] Tue Jul 30 07:49:54 JST 2013 [GC 1291046K->695141K(1280320K), 0.0056460 secs] Tue Jul 30 07:49:54 JST 2013 [Full GC 695141K->253260K(1280320K), 0.3171460 secs] Tue Jul 30 07:49:56 JST 2013 [GC 829922K->258097K(1260736K), 0.0055120 secs] Tue Jul 30 07:49:58 JST 2013 [GC 814897K->261155K(1240896K), 0.0060600 secs]
ログの各行は左から順に
- タイムスタンプ
- GC前のメモリ量
- GC後のメモリ量
- GCによって開放されたメモリ量
- GC処理にかかった時間
となっています。また、Full GCが行われた場合には上の例の5行目のように「Full GC」と記録されます。
今回解析の対象とするGCログは実際のScutumサーバのもので、約17日分、68万行のデータになります。
設定ファイルを記述する
Dunkheadはシンプルさを重視しており、ほぼ何も設定せずに使えるように作られています。しかし、唯一毎回きちんとデータに合わせて設定しなければいけないのが、タイムスタンプについての項目です。「ログファイルの各行について、どの部分が、どんなフォーマットで日時を表しているか?」については、解析するエンジニアがきちんと設定ファイルに記述する必要があります。
今回のデータでは、下記の太字の部分がタイムスタンプにあたります。
Tue Jul 30 07:49:39 JST 2013 [GC 1346804K->683119K(1344768K), 0.0071550 secs]
Dunkheadでは設定ファイルはJSON形式となっています。datetime項目以下に、formatとregexという2つの項目を記述します。
formatは「日時がどのようなフォーマットで表現されているか」を指定するもので、記述方法はこちらのJavaのSimpleDateFormatクラスでの定義に従います。今回の例ではEEE MMM d HH:mm:ss z yyyyとしました。
regexはデータの各行について、タイムスタンプ部分にマッチするような正規表現となります。正規表現の実装はJavaを使用しており、細かい定義についてはJavaのPatternクラスでの定義に従います。今回の例ではタイムスタンプ部はログの各行において一番左の28バイトで固定であるため、単純に^.{28}としました。
最もシンプルな形での設定ファイル(dunkhead.conf)の内容は以下のようになります。
{
"datetime": {
"format": "EEE MMM d HH:mm:ss z yyyy",
"regex": "^.{28}"
},
"fields": []
}
全体のGCの件数を可視化する
設定ファイルを前項の内容で保存したら、以下のようにhadoopスクリプトのjarオプションを使って実行します。dunkhead.jarとdunkhead.confはカレントディレクトリに、入力となるGCのログファイルは/hadoop/gc/以下に、そして画像の出力先は/tmp/output/であるものとします。/tmp/output/は実行前に削除しておいてください。
bin/hadoop jar dunkhead.jar /hadoop/gc/ /tmp/output/ dunkhead.conf
出力される画像は以下のようになります。
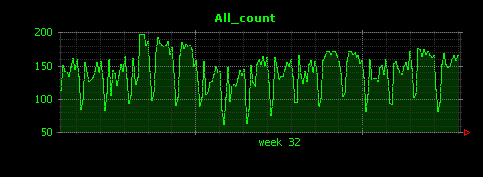
縦軸の数字は「5分間の平均GC回数」を示すことになります。多いときには5分間に200回なので、毎分40回、およそ1.5秒に1回はGCが行われていることがわかります。また、HTTPのアクセスが減る夜間は、GCの回数も明らかに減少するようです。
Full GCの頻度を可視化する
次に、Full GCに注目して時系列での発生状況を可視化してみます。設定ファイルを次のようにします。
{
"datetime": {
"format": "EEE MMM d HH:mm:ss z yyyy",
"regex": "^.{28}"
},
"fields": [
{
"name": "Full GC",
"regex": "Full GC",
"type": "count"
}
]
}
すると次のように毎5分ごとのFull GCの発生回数が可視化されます。
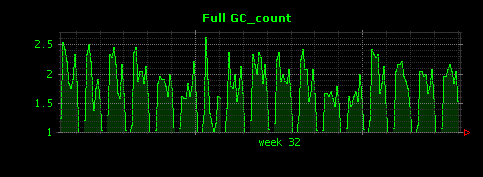
Full GCは2分に1回程度の頻度で発生していることがわかります。また、前項のGC全体の発生頻度のグラフと比較すると、Full GCとGC全体の数の間には、負の相関がありそうなことがわかります。
GC前のメモリ量を可視化する
次に、GC処理が行われる前のメモリの量について可視化します。GC前のメモリ量は、下記の太字の部分です。
Tue Jul 30 07:49:39 JST 2013 [GC 1346804K->683119K(1344768K), 0.0071550 secs]
「GC」という文字と半角スペースに続いて存在している数字なので、設定ファイルを以下のように記述します。
{
"datetime": {
"format": "EEE MMM d HH:mm:ss z yyyy",
"regex": "^.{28}"
},
"fields": [
{
"name": "MemoryBeforeGC",
"regex": "GC ([0-9]+)K",
"eval": "$1 * 1024",
"type": "average"
}
]
}
データ内の値の単位は、右側に「K」と書いてあることからもわかりますが、KBとなっています。そこで、eval項目の内容を「$1 * 1024」とし、グラフに描画する際の単位をバイトにしておきます。このように、eval項目では演算子等を使って値の計算を行うことができるようになっています。
ここではGC前のメモリ量の平均値を可視化します。typeの値はaverageになっています。これによって次のようなグラフが出力されます。
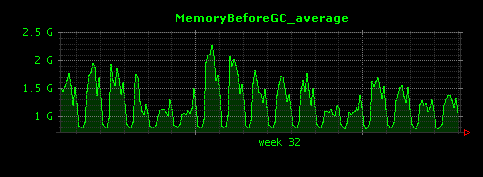
朝から夜までのアクセス数が多い時間では、GC前のメモリの量は1〜2GBほどで、深夜は数百MBが平均値であることがわかります。
上記は平均値でしたが、次にGC前のメモリ量について、最大値と最小値についても可視化してみます。設定ファイルを次のようにします。
{
"datetime": {
"format": "EEE MMM d HH:mm:ss z yyyy",
"regex": "^.{28}"
},
"fields": [
{
"name": "MemoryBeforeGC",
"regex": "GC ([0-9]+)K",
"eval": "$1 * 1024",
"type": "average"
},
{
"name": "MemoryBeforeGC",
"regex": "GC ([0-9]+)K",
"eval": "$1 * 1024",
"type": "max"
},
{
"name": "MemoryBeforeGC",
"regex": "GC ([0-9]+)K",
"eval": "$1 * 1024",
"type": "min"
}
]
}
すると、次のようにGC前のメモリ量の5分毎の最大値と最小値についてもそれぞれ出力されるようになります。
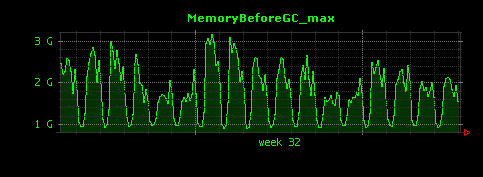
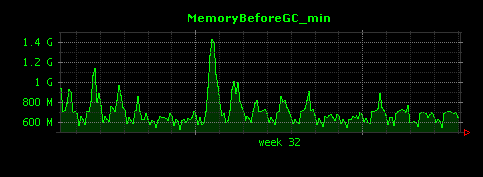
GC前の最大値は約3GBになることがわかります。また、グラフ中の2週目の初日はなぜかGC前のメモリ量の最小値が飛び抜けて大きく、1.4GBになっていることがわかります。
GC後のメモリ量を可視化する
GC後のメモリ量についても、同様に平均・最大・最小の3つについて可視化してみます。GC後の値は、データ中、下記の太字の部分です。
Tue Jul 30 07:49:54 JST 2013 [GC 1291046K->695141K(1280320K), 0.0056460 secs]
設定ファイルは次のようになります。
{
"datetime": {
"format": "EEE MMM d HH:mm:ss z yyyy",
"regex": "^.{28}"
},
"fields": [
{
"name": "MemoryAfterGC",
"regex": "->([0-9]+)K",
"eval": "$1 * 1024",
"type": "average"
},
{
"name": "MemoryAfterGC",
"regex": "->([0-9]+)K",
"eval": "$1 * 1024",
"type": "max"
},
{
"name": "MemoryAfterGC",
"regex": "->([0-9]+)K",
"eval": "$1 * 1024",
"type": "min"
}
]
}
出力される画像は以下の3つです。
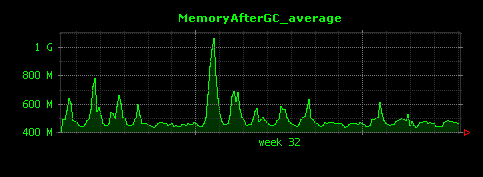
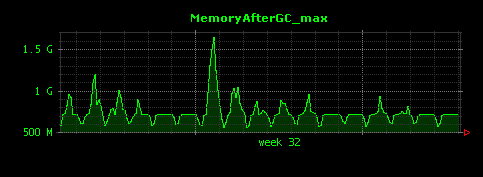
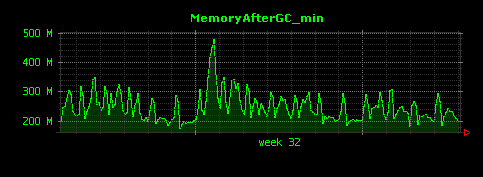
GC後のメモリ量は、平均して500MB程度であることがわかります。グラフ中、大きなピークが存在する二週目の初日は、GC後もメモリの量があまり減っていないことがわかります。仮にこれが全く想定していない挙動であれば、より詳細な調査が必要となる可能性があります。しかし、GC後のメモリ量の最小値(一番下のグラフ)を見てみると、問題の日もGC後は450MB程度の値となっていることが確認できるため、特に大きなメモリリークが起きているようなことはなさそうです。平均値・最大値・最小値の3つ全てを見てみることが大事であることがわかります。
GCに要した時間を可視化する
次に、GC処理にかかった時間について可視化してみます。データ中、下記の太字の部分がGCに要した時間となっています。
Tue Jul 30 07:49:58 JST 2013 [GC 814897K->261155K(1240896K), 0.0060600 secs]
単位は秒ですが、数値がやや小さすぎるので、ここでは1000倍してミリ秒でグラフを描いてみることにします。設定ファイルは次のようになります。
{
"datetime": {
"format": "EEE MMM d HH:mm:ss z yyyy",
"regex": "^.{28}"
},
"fields": [
{
"name": "GC-Time",
"regex": ", ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "average"
},
{
"name": "GC-Time",
"regex": ", ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "max"
},
{
"name": "GC-Time",
"regex": ", ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "min"
}
]
}
出力される画像は以下のようになります。
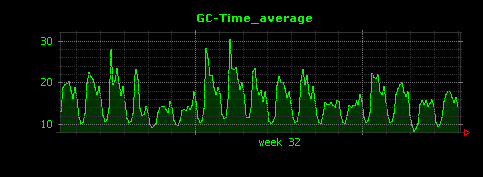
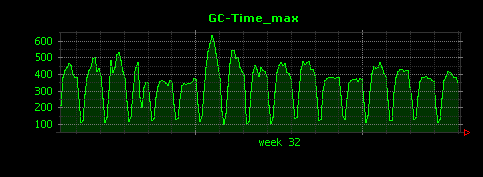
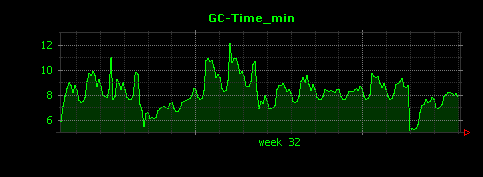
平均値(一番上のグラフ)を見ると、最も負荷が高い時間でもGCに要する時間はわずか30ミリ秒となっており、問題なさそうです。メモリ量にピークが存在していた第二週目の初日についても、GCに要した時間はそれほど大きな変化は見られず、異常なさそうです。
しかし最大値(真ん中のグラフ)を見てみると、重いGCについては最大で400から600ミリ秒と、平均値の20倍程度の時間を要していることがわかります。これは、もしかしたらFull GCかもしれません。そこで、次にFull GCのみについて、GCに要した時間を可視化してみることにします。
Full GCに要した時間を可視化する
Full GCの場合、データは次のようになります。
Tue Jul 30 07:49:54 JST 2013 [Full GC 695141K->253260K(1280320K), 0.3171460 secs]
そこで、次のように設定ファイルを書き換えます。
{
"datetime": {
"format": "EEE MMM d HH:mm:ss z yyyy",
"regex": "^.{28}"
},
"fields": [
{
"name": "Full GC-Time",
"regex": "Full.*, ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "average"
},
{
"name": "Full GC-Time",
"regex": "Full.*, ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "max"
},
{
"name": "Full GC-Time",
"regex": "Full.*, ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "min"
}
]
}
出力される画像は以下のようになります。
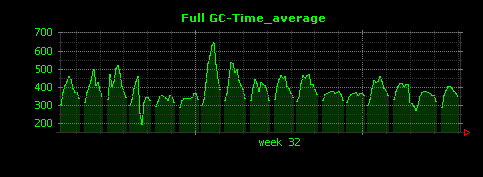
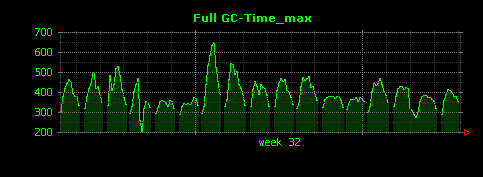
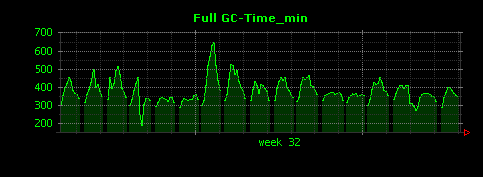
3つのグラフは殆ど同じ出力となりました。これは、本エントリの最初の方で調べたように、5分間で起こるFull GCの数が平均して1〜2回程度と少なく、またFull GCに要する時間にばらつきが少ないことが原因だと考えられます。そこで、Full GCではない、マイナーGCについても同様にグラフを出力してみます。
マイナーGCに要した時間を可視化する
マイナーGCの場合、データは必ず次のように[GCという文字列を含みます。
Tue Jul 30 07:49:58 JST 2013 [GC 814897K->261155K(1240896K), 0.0060600 secs]
そこで、設定ファイルを次のように記述します。
{
"datetime": {
"format": "EEE MMM d HH:mm:ss z yyyy",
"regex": "^.{28}"
},
"fields": [
{
"name": "Minor GC-Time",
"regex": "\\[GC .*, ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "average"
},
{
"name": "Minor GC-Time",
"regex": "\\[GC .*, ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "max"
},
{
"name": "Minor GC-Time",
"regex": "\\[GC .*, ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "min"
}
]
}
出力される画像は次のようになります。
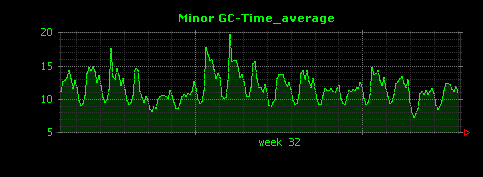
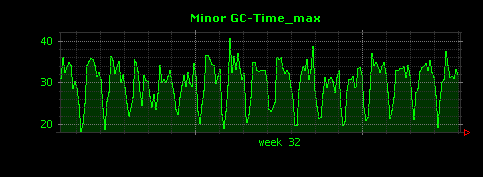
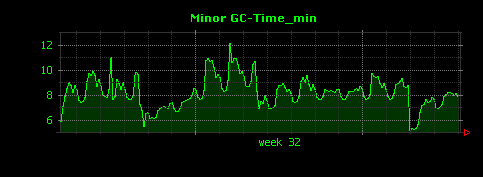
マイナーGCに要した時間は、最大値(2つめのグラフ)でも30ミリ秒前後と短く、予想通り、Full GCとマイナーGCの違いが大きく存在していることがわかりました。
すべての可視化を1度にまとめて行う
本エントリで行ってきた可視化を、一度のHadoop処理で終わらせる場合には、設定ファイルを次のように記述します。fields項目に、すべての記述を行います。
{
"datetime": {
"format": "EEE MMM d HH:mm:ss z yyyy",
"regex": "^.{28}"
},
"fields": [
{
"name": "Full GC",
"regex": "Full GC",
"type": "count"
},
{
"name": "MemoryBeforeGC",
"regex": "GC ([0-9]+)K",
"eval": "$1 * 1024",
"type": "average"
},
{
"name": "MemoryBeforeGC",
"regex": "GC ([0-9]+)K",
"eval": "$1 * 1024",
"type": "max"
},
{
"name": "MemoryBeforeGC",
"regex": "GC ([0-9]+)K",
"eval": "$1 * 1024",
"type": "min"
},
{
"name": "MemoryAfterGC",
"regex": "->([0-9]+)K",
"eval": "$1 * 1024",
"type": "average"
},
{
"name": "MemoryAfterGC",
"regex": "->([0-9]+)K",
"eval": "$1 * 1024",
"type": "max"
},
{
"name": "MemoryAfterGC",
"regex": "->([0-9]+)K",
"eval": "$1 * 1024",
"type": "min"
},
{
"name": "GC-Time",
"regex": ", ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "average"
},
{
"name": "GC-Time",
"regex": ", ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "max"
},
{
"name": "GC-Time",
"regex": ", ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "min"
},
{
"name": "Full GC-Time",
"regex": "Full.*, ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "average"
},
{
"name": "Full GC-Time",
"regex": "Full.*, ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "max"
},
{
"name": "Full GC-Time",
"regex": "Full.*, ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "min"
},
{
"name": "Minor GC-Time",
"regex": "\\[GC .*, ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "average"
},
{
"name": "Minor GC-Time",
"regex": "\\[GC .*, ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "max"
},
{
"name": "Minor GC-Time",
"regex": "\\[GC .*, ([0-9\\.]+) secs",
"eval": "$1 * 1000",
"type": "min"
}
]
}
今回解析対象とした68万行のGCログデータの場合、上記設定で、Hadoopのスタンドアロンモードで約2分15秒で解析が終了します。
まとめ
今回は、Hadoop上で手軽にデータを可視化するためのソフトウェア、Dunkheadを使い、Scutumで実際に記録した、JavaのGCのログファイルを解析してみました。GCに要している時間やメモリ量の変動、Full GCとマイナーGCの違いなどを、視覚的に簡単に掴むことができました。
このようにDunkheadを使うと、grepか、あるいはegrepを行うような気軽さ(簡単な設定ファイルの記述のみ)で、さまざまな視点からデータを可視化できるようになります。Dunkheadによって可視化された画像から異常や傾向を掴み、さらに深く解析していく場合には、そのためのコードを書くなどして、よりそのデータに特化した解析を行っていくことになるでしょう。Dunkheadはまず全体の概要を掴み、解析の入り口を掴むヒントを得るために使います。タイムスタンプ付きのログファイルであれば、ウェブサーバのアクセスログのようなものや、今回解析したGCのログなど、さまざまなデータについて簡単に可視化することができます。
GCのログは専用のGUIのツールなどを使って解析することもできますが、Dunkheadの大きなメリットは、Hadoop上で動作するため、ログファイルのサイズが非常に大きい場合(数百GB,あるいはそれ以上)でも使うことができる、という点です。また、サーバやクラウド上で解析を行うことが可能であり、複数のサーバから収集したGCログをすべてまとめて解析することができる点もメリットです。
本エントリについてのフィードバック等ありましたら、お気軽に@kinyukaまでお寄せください。