技術者ブログ
クラウド型WAF「Scutum(スキュータム)」の開発者/エンジニアによるブログです。
金床“Kanatoko”をはじめとする株式会社ビットフォレストの技術チームが、“WAFを支える技術”をテーマに幅広く、不定期に更新中!
top/vmstatの出力をHadoopとDunkheadで可視化し、Linuxシステムの負荷状況を把握する
はじめに
Dunkheadはタイムスタンプ付きのテキストデータ(アクセスログなど)を手軽に可視化するためのソフトウェアです。Hadoop上で動作するため、データのサイズが大きい、いわゆるビッグデータの場合にも使用することができます。
今回はtopとvmstatの出力を時系列のログファイルとして扱い、Linuxシステムの負荷状況について、Dunkheadを使って可視化してみたいと思います。

プロセス毎のCPU使用率を可視化する
topの標準出力をファイルに記録するために、-bオプションを使ってバッチモードで実行します。また、インターバルを5秒にするため、-dオプションに引数として5を与えます。またtopが各行末に付ける余分なスペースの削除と、タイムスタンプを付加するために、下記のようにRubyを使用します。
top -b -d 5 | ruby -ne '$line = $_.sub( / +$/, "" ); puts "#{Time.new} #{$line}"'
これによって5秒ごとにtopが実行され、結果がタイムスタンプ付きで標準出力に吐かれるようになります。出力の例を以下に示します。
2013-08-17 19:50:49 +0900 top - 19:50:49 up 6 days, 11:41, 32 users, load average: 0.71, 0.91, 1.03 2013-08-17 19:50:49 +0900 Tasks: 395 total, 1 running, 393 sleeping, 0 stopped, 1 zombie 2013-08-17 19:50:49 +0900 Cpu(s): 3.7%us, 3.0%sy, 0.1%ni, 93.0%id, 0.1%wa, 0.0%hi, 0.0%si, 0.0%st 2013-08-17 19:50:49 +0900 Mem: 16249236k total, 15041056k used, 1208180k free, 955632k buffers 2013-08-17 19:50:49 +0900 Swap: 0k total, 0k used, 0k free, 4768264k cached 2013-08-17 19:50:49 +0900 PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 2013-08-17 19:50:49 +0900 5318 root 10 -10 1348m 271m 251m S 20 1.7 2253:05 vmware-vmx 2013-08-17 19:50:49 +0900 4020 root 20 0 363m 240m 28m S 12 1.5 738:07.35 Xorg 2013-08-17 19:50:49 +0900 10481 kanatoko 20 0 234m 25m 16m S 8 0.2 624:17.57 gnome-system-mo 2013-08-17 19:50:49 +0900 10480 root 20 0 19244 1464 908 R 2 0.0 0:00.01 top 2013-08-17 19:50:49 +0900 28774 kanatoko 20 0 1723m 1.2g 31m S 2 7.4 221:39.71 firefox-bin 2013-08-17 19:50:49 +0900 1 root 20 0 4104 848 556 S 0 0.0 0:01.04 init 2013-08-17 19:50:49 +0900 2 root 15 -5 0 0 0 S 0 0.0 0:00.00 kthreadd 2013-08-17 19:50:49 +0900 3 root RT -5 0 0 0 S 0 0.0 0:00.06 migration/0 2013-08-17 19:50:49 +0900 4 root 15 -5 0 0 0 S 0 0.0 0:12.59 ksoftirqd/0 2013-08-17 19:50:49 +0900 5 root RT -5 0 0 0 S 0 0.0 0:00.00 watchdog/0 2013-08-17 19:50:49 +0900 6 root RT -5 0 0 0 S 0 0.0 0:00.03 migration/1 2013-08-17 19:50:49 +0900 7 root 15 -5 0 0 0 S 0 0.0 3:19.86 ksoftirqd/1 2013-08-17 19:50:49 +0900 8 root RT -5 0 0 0 S 0 0.0 0:00.00 watchdog/1
私の開発用のマシンにおいて、上記topコマンドを3日間実行し続けたところ、2000万行、サイズは1.8GBのログファイルが生成されました。今回はこのデータについて可視化を行ってみます。
まずはCPUの消費に注目してみます。設定ファイルを次のように記述します。
{
"datetime": {
"format": "yyyy-MM-dd HH:mm:ss Z",
"regex": "^.{25}"
},
"fields": [
{
"name": "$1-$3",
"regex": " \\+0900[ ]+([0-9]+).*([0-9]+)[ ]+[0-9\\.]+[ ]+[0-9\\.:]+[ ]+([^ ]+)",
"type": "average",
"eval": "$2"
}
]
}
name項目の値は『$1-$3』となっています。このうち$1はregex項目の1つめのグループの値で、プロセスIDを示します。$3は同じくregex項目中の3つめのグループ(一番右の値)であり、コマンド名(vmware-vmxやXorgのような、プロセス名)を示します。$1と$3の間のハイフンは単に区切り文字列として使われており、減算が行われるわけではありません。このname項目の値はMap処理におけるキーとして働き、キーごとに可視化が行われます。つまりプロセスIDとプロセス名を結びつけた文字列がキーとして働くことになります。基本的には各プロセスについて注目すべき場面であるため、$1だけ(プロセスIDだけ)をキーとしても本質的には問題ないのですが、このようにプロセス名もキーに含んでおくことで、そのプロセスIDがいったい何のプロセスなのかがわかりやすくなります。
eval項目の値は$2となっており、これはregex項目中の2番目のグループの値であり、CPU使用率となります。
type項目の値はaverageとなっており、CPU使用率について単位時間当たりの平均値をグラフ化する、という意味になります。
上記設定ファイルを使ってDunkheadを実行すると1172個の画像ファイルが生成されました。その中からいくつかピックアップします。
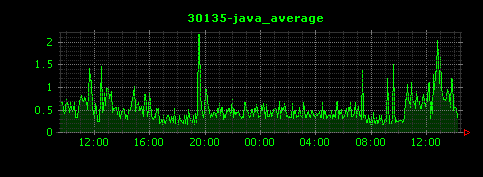
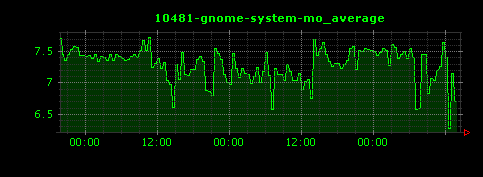
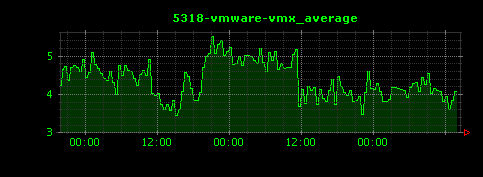
上から順番にjava、gnome-system-monitor、vmware-vmxのCPU使用率のグラフになります。縦軸の単位はCPU使用率のパーセントです。比較的システムリソースを消費していないという、あまり可視化に向かない結果となってしまいました。
プロセス毎のメモリ使用率を可視化する
続いて、メモリ使用率について可視化を行ってみます。設定ファイルの内容はCPUの場合とほぼ同じです。
{
"datetime": {
"format": "yyyy-MM-dd HH:mm:ss Z",
"regex": "^.{25}"
},
"fields": [
{
"name": "$1-$3",
"regex": " \\+0900[ ]+([0-9]+).*[0-9]+[ ]+([0-9\\.])+[ ]+[0-9\\.:]+[ ]+([^ ]+)",
"type": "average",
"eval": "$2"
}
]
}
以下のような、縦軸がメモリ使用率を表す画像が出力されます。それぞれjava、chrome、vmware-vmx、firefoxの各プロセスの様子を示します。
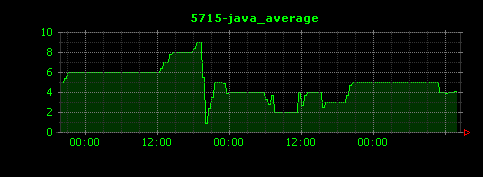
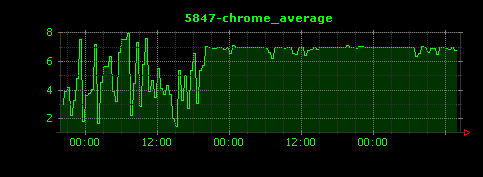
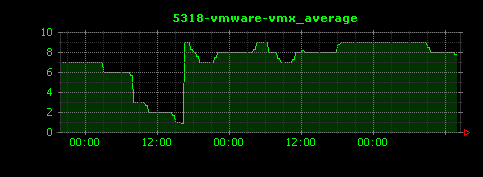
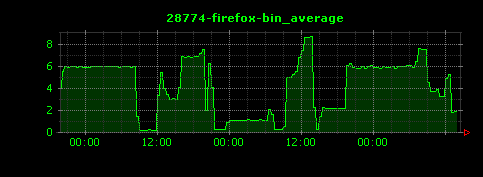
タスク数(プロセス数)を可視化する
次に、システム全体のタスク数(プロセス数)が時系列でどのように変化したのかを可視化してみます。topの出力には以下のような、タスクに注目した行が含まれています。この行から、総タスク数(太字の部分)の値を取得し、可視化対象とします。
2013-08-17 19:50:49 +0900 Tasks: 395 total, 1 running, 393 sleeping, 0 stopped, 1 zombie
設定ファイルは次のようになります。今回はキーが一種類だけであり、処理対象の行数は多くなりません。そこでcombiner.inmemory項目を指定し、H2の処理をメモリ上で行うことで処理を高速化します。
{
"combiner.inmemory": true,
"datetime": {
"format": "yyyy-MM-dd HH:mm:ss Z",
"regex": "^.{25}"
},
"fields": [
{
"name": "TotalTasks",
"regex": "Tasks:[ ]*([0-9]+)[ ]*total",
"type": "average",
"eval": "$1"
}
]
}
以下のようにタスク数が可視化されます。ログを取った3日間の間、約390〜440くらいのプロセスが稼働していたことがわかります。
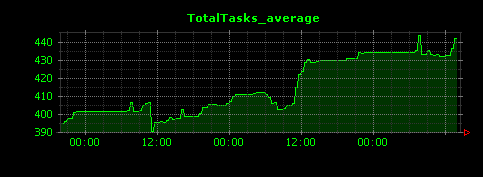
vmstatの出力を可視化する
次に、vmstatコマンドの結果について可視化を行ってみます。
vmstatはデフォルトでは出力にタイムスタンプを含みませんが、バージョン3.2.8以降では、-tオプションによってタイムスタンプを付加することができるようになっています。
[#]vmstat -version
usage: vmstat [-V] [-n] [delay [count]]
-V prints version.
-n causes the headers not to be reprinted regularly.
-a print inactive/active page stats.
-d prints disk statistics
-D prints disk table
-p prints disk partition statistics
-s prints vm table
-m prints slabinfo
-t add timestamp to output
-S unit size
delay is the delay between updates in seconds.
unit size k:1000 K:1024 m:1000000 M:1048576 (default is K)
count is the number of updates.
Scutumサーバ上で「vmstat -t 1」を実行し、約25日間分のログを取得しました。データサイズは約220MB、約210万行です。vmstatの出力の例を以下に示します。
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ ---timestamp--- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 288 8007692 1429248 22736432 0 0 0 6 0 0 4 0 96 0 0 2013-08-01 14:32:31 JST 0 0 288 8018604 1429248 22736432 0 0 0 0 3001 6689 7 0 93 0 0 2013-08-01 14:32:32 JST 1 0 288 8033484 1429248 22736432 0 0 0 16 3882 8627 10 0 90 0 0 2013-08-01 14:32:33 JST 3 0 288 8033700 1429248 22736432 0 0 0 0 3164 6337 5 0 95 0 0 2013-08-01 14:32:34 JST 1 0 288 8032892 1429248 22736432 0 0 0 328 3872 7802 8 0 92 0 0 2013-08-01 14:32:35 JST 6 0 288 8032880 1429248 22736432 0 0 0 336 5172 10080 11 1 89 0 0 2013-08-01 14:32:36 JST 0 0 288 8032872 1429248 22737020 0 0 0 16 5243 10142 10 1 89 0 0 2013-08-01 14:32:37 JST 1 0 288 8032872 1429248 22737020 0 0 0 0 3437 6644 6 0 94 0 0 2013-08-01 14:32:38 JST
今回はI/O、system、CPU関連の項目について可視化を行ってみることにします。bi、bo、in、cs、us、sy、id、waの8項目について、以下のようにfields内にまとめて定義した形で設定ファイルを記述します。
{
"combiner.inmemory": true,
"datetime": {
"format": "yyyy-MM-dd HH:mm:ss",
"regex": ".{19} JST$"
},
"fields": [
{
"name": "bi-BlocksIn",
"regex": "[ ]*(?:[0-9]+[ ]+){8}([0-9]+)",
"type": "average"
},
{
"name": "bo-BlocksOut",
"regex": "[ ]*(?:[0-9]+[ ]+){9}([0-9]+)",
"type": "average"
},
{
"name": "in-Interrupts",
"regex": "[ ]*(?:[0-9]+[ ]+){10}([0-9]+)",
"type": "average"
},
{
"name": "cs-ContextSwitches",
"regex": "[ ]*(?:[0-9]+[ ]+){11}([0-9]+)",
"type": "average"
},
{
"name": "us-UserTime",
"regex": "[ ]*(?:[0-9]+[ ]+){12}([0-9]+)",
"type": "average"
},
{
"name": "sy-SystemTime",
"regex": "[ ]*(?:[0-9]+[ ]+){13}([0-9]+)",
"type": "average"
},
{
"name": "id-IdleTime",
"regex": "[ ]*(?:[0-9]+[ ]+){14}([0-9]+)",
"type": "average"
},
{
"name": "wa-WaitTime",
"regex": "[ ]*(?:[0-9]+[ ]+){15}([0-9]+)",
"type": "average"
}
]
}
Dunkheadを実行すると、一度の処理で8項目すべてについて可視化が完了します。
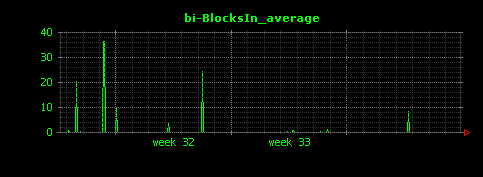
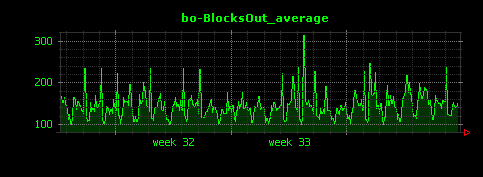
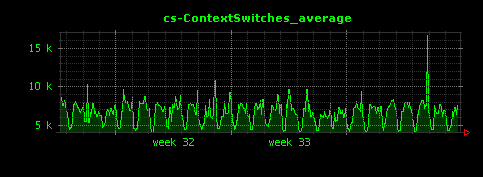
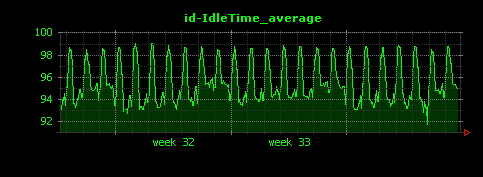
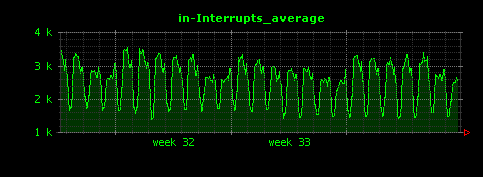
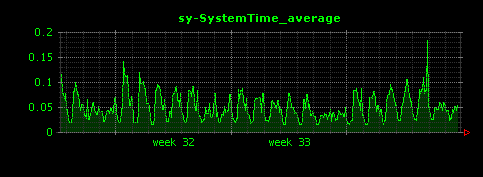
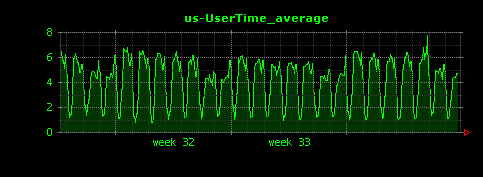
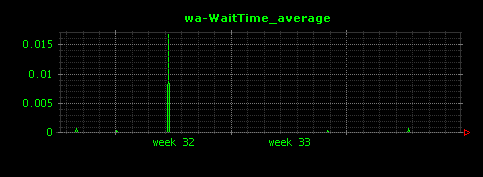
昼夜できれいに負荷が分かれていることがよくわかります。I/Oについては、読み込みが殆ど無く、書き込みはシステム負荷と連動した形で発生していることがわかります。これはアクセスログファイルへの書き込みだと考えられます。また、ScutumはマルチスレッドのJavaサーバアプリケーションであるため、コンテキストスイッチはやや高めで推移していることもわかります。
まとめ
今回はDunkheadを使い、topやvmstatといったシステム管理者に馴染みの深いコマンドの出力を可視化してみました。
システムの監視の現場では、統合的かつリアルタイムにこのようなシステム負荷の可視化を行っているケースが多いと思います。しかし、たとえばテスト環境のサーバや、一時的に急いで立てたサーバなど、監視システムに統合できないままの環境が存在することも考えられます。そのような場合、今回の例のように、とりあえずコマンドの実行結果をログファイルに溜めておき、後から必要に応じて可視化を行うということが可能になります。また、リアルタイムで多くの項目を可視化してしまうとかえって監視が分かりづらくなるため、細かなデータについてはログファイルに溜めておき、必要になった際にDunkheadで可視化する、というアプローチもよいでしょう。
Dunkheadのその他の使用例についてはこちらで紹介しています。また、ソースコードはGithubにて公開中です。Dunkheadに関するフィードバックはお気軽に@kinyukaまで。