技術者ブログ
クラウド型WAF「Scutum(スキュータム)」の開発者/エンジニアによるブログです。
金床“Kanatoko”をはじめとする株式会社ビットフォレストの技術チームが、“WAFを支える技術”をテーマに幅広く、不定期に更新中!
HadoopとDunkheadでNASAのウェブサーバのアクセスログを解析・可視化する
内容の一覧
今回のエントリは内容が長いため、それぞれの項目へのリンクを下記にまとめました。
はじめに生のデータを見てタイムスタンプ部のフォーマットを確認する
データ全体を可視化する
ステータスコード404について注目して可視化を行う
すべてのステータスコードについて可視化する
単位時間を変更する
うまく可視化されないデータを無視する
HTTPメソッド別のアクセス状況を可視化する
ファイル種別ごとのアクセス状況を可視化する
HTTPレスポンスのサイズについて可視化する
ファイル種別ごとのHTTPレスポンスサイズを可視化する
コンテンツ別のアクセス状況を可視化する
期間別(日別)のアクセス状況を可視化する
まとめ
はじめに
Dunkheadはタイムスタンプ付きのテキストデータ(アクセスログなど)を手軽に可視化するためのソフトウェアです。Hadoop上で動作するため、データのサイズが大きい、いわゆるビッグデータの場合にも使用することができます。
本エントリでは、ウェブ上で手に入れることができるNASAのウェブサーバのアクセスログを例に、Dunkheadでの可視化がどのように行われるのかを見ていきます。

アクセスログは1995年のもので、展開すると200MB程あり、約190万行からなります。今の感覚では非常に小さなデータセットであり、わざわざHadoopを使うほどの規模ではありません。しかしDunkheadの使い方はデータが小さくても大きくてもあまり変わらないので、今回はこのデータを使うことにします。
生のデータを見てタイムスタンプ部のフォーマットを確認する
Dunkheadでデータを可視化する場合、まずは生のデータがどのようなものなのか、先頭の数十行程度でもよいので、実際にエディタで確認します。今回はウェブサーバのアクセスログということで、エンジニアの方には非常に馴染みが深いフォーマットになっています。
199.72.81.55 - - [01/Jul/1995:00:00:01 -0400] "GET /history/apollo/ HTTP/1.0" 200 6245 unicomp6.unicomp.net - - [01/Jul/1995:00:00:06 -0400] "GET /shuttle/countdown/ HTTP/1.0" 200 3985 199.120.110.21 - - [01/Jul/1995:00:00:09 -0400] "GET /shuttle/missions/sts-73/mission-sts-73.html HTTP/1.0" 200 4085 burger.letters.com - - [01/Jul/1995:00:00:11 -0400] "GET /shuttle/countdown/liftoff.html HTTP/1.0" 304 0 199.120.110.21 - - [01/Jul/1995:00:00:11 -0400] "GET /shuttle/missions/sts-73/sts-73-patch-small.gif HTTP/1.0" 200 4179 burger.letters.com - - [01/Jul/1995:00:00:12 -0400] "GET /images/NASA-logosmall.gif HTTP/1.0" 304 0 burger.letters.com - - [01/Jul/1995:00:00:12 -0400] "GET /shuttle/countdown/video/livevideo.gif HTTP/1.0" 200 0 205.212.115.106 - - [01/Jul/1995:00:00:12 -0400] "GET /shuttle/countdown/countdown.html HTTP/1.0" 200 3985 d104.aa.net - - [01/Jul/1995:00:00:13 -0400] "GET /shuttle/countdown/ HTTP/1.0" 200 3985 129.94.144.152 - - [01/Jul/1995:00:00:13 -0400] "GET / HTTP/1.0" 200 7074 unicomp6.unicomp.net - - [01/Jul/1995:00:00:14 -0400] "GET /shuttle/countdown/count.gif HTTP/1.0" 200 40310 unicomp6.unicomp.net - - [01/Jul/1995:00:00:14 -0400] "GET /images/NASA-logosmall.gif HTTP/1.0" 200 786 unicomp6.unicomp.net - - [01/Jul/1995:00:00:14 -0400] "GET /images/KSC-logosmall.gif HTTP/1.0" 200 1204 d104.aa.net - - [01/Jul/1995:00:00:15 -0400] "GET /shuttle/countdown/count.gif HTTP/1.0" 200 40310 d104.aa.net - - [01/Jul/1995:00:00:15 -0400] "GET /images/NASA-logosmall.gif HTTP/1.0" 200 786 d104.aa.net - - [01/Jul/1995:00:00:15 -0400] "GET /images/KSC-logosmall.gif HTTP/1.0" 200 1204 129.94.144.152 - - [01/Jul/1995:00:00:17 -0400] "GET /images/ksclogo-medium.gif HTTP/1.0" 304 0 199.120.110.21 - - [01/Jul/1995:00:00:17 -0400] "GET /images/launch-logo.gif HTTP/1.0" 200 1713 ppptky391.asahi-net.or.jp - - [01/Jul/1995:00:00:18 -0400] "GET /facts/about_ksc.html HTTP/1.0" 200 3977 net-1-141.eden.com - - [01/Jul/1995:00:00:19 -0400] "GET /shuttle/missions/sts-71/images/KSC-95EC-0916.jpg HTTP/1.0" 200 34029 ppptky391.asahi-net.or.jp - - [01/Jul/1995:00:00:19 -0400] "GET /images/launchpalms-small.gif HTTP/1.0" 200 11473 205.189.154.54 - - [01/Jul/1995:00:00:24 -0400] "GET /shuttle/countdown/ HTTP/1.0" 200 3985 waters-gw.starway.net.au - - [01/Jul/1995:00:00:25 -0400] "GET /shuttle/missions/51-l/mission-51-l.html HTTP/1.0" 200 6723 ppp-mia-30.shadow.net - - [01/Jul/1995:00:00:27 -0400] "GET / HTTP/1.0" 200 7074 205.189.154.54 - - [01/Jul/1995:00:00:29 -0400] "GET /shuttle/countdown/count.gif HTTP/1.0" 200 40310 alyssa.prodigy.com - - [01/Jul/1995:00:00:33 -0400] "GET /shuttle/missions/sts-71/sts-71-patch-small.gif HTTP/1.0" 200 12054 ppp-mia-30.shadow.net - - [01/Jul/1995:00:00:35 -0400] "GET /images/ksclogo-medium.gif HTTP/1.0" 200 5866 dial22.lloyd.com - - [01/Jul/1995:00:00:37 -0400] "GET /shuttle/missions/sts-71/images/KSC-95EC-0613.jpg HTTP/1.0" 200 61716 smyth-pc.moorecap.com - - [01/Jul/1995:00:00:38 -0400] "GET /history/apollo/apollo-13/images/70HC314.GIF HTTP/1.0" 200 101267 205.189.154.54 - - [01/Jul/1995:00:00:40 -0400] "GET /images/NASA-logosmall.gif HTTP/1.0" 200 786
1995年らしく、アクセス元のIPアドレスが逆引きされているのが非常に新鮮です。
Dunkheadはシンプルさを重視しており、ほぼ何も設定せずに使えるように作られています。しかし、唯一毎回きちんとデータに合わせて設定しなければいけないのが、タイムスタンプについての項目です。「ログファイルの各行について、どの部分が、どんなフォーマットで日時を表しているか?」については、解析するエンジニアがきちんと設定ファイルに記述する必要があります。
今回のデータでは、下記の太字の部分がタイムスタンプにあたります。
199.72.81.55 - - [01/Jul/1995:00:00:01 -0400] "GET /history/apollo/ HTTP/1.0" 200 6245 unicomp6.unicomp.net - - [01/Jul/1995:00:00:06 -0400] "GET /shuttle/countdown/ HTTP/1.0" 200 3985 199.120.110.21 - - [01/Jul/1995:00:00:09 -0400] "GET /shuttle/missions/sts-73/mission-sts-73.html HTTP/1.0" 200 4085 burger.letters.com - - [01/Jul/1995:00:00:11 -0400] "GET /shuttle/countdown/liftoff.html HTTP/1.0" 304 0 199.120.110.21 - - [01/Jul/1995:00:00:11 -0400] "GET /shuttle/missions/sts-73/sts-73-patch-small.gif HTTP/1.0" 200 4179 burger.letters.com - - [01/Jul/1995:00:00:12 -0400] "GET /images/NASA-logosmall.gif HTTP/1.0" 304 0
そこで、JSON形式の設定ファイルのdatetime項目以下に、formatとregexという2つの項目を記述します。
formatは「日時がどのようなフォーマットで表現されているか」を指定するもので、記述方法はこちらのJavaのSimpleDateFormatクラスでの定義に従います。今回の例では [dd/MMM/yyyy:HH:mm:ss Z] としました。
regexはデータの各行について、タイムスタンプ部分にマッチするような正規表現となります。正規表現の実装はJavaを使用しており、細かい定義についてはJavaのPatternクラスでの定義に従います。今回の例では \\[[0-9]{2}/[^\\]]+\\] としました。
設定ファイル(dunkhead.conf)の内容は以下のようになります。
{
"datetime" :
{
"format" : " [dd/MMM/yyyy:HH:mm:ss Z] ",
"regex" : " \\[[0-9]{2}/[^\\]]+\\] "
}
}
regex項目はいろいろな書き方、マッチングのさせ方が存在するので、上記はあくまで一例になります。別の記述例として、例えば01/Jul/1995:00:00:01 -0400の部分はかならず26文字であることから、次のように書くこともできます。
{
"datetime": {
"format": " [dd/MMM/yyyy:HH:mm:ss Z] ",
"regex": " \\[.{26}\\] "
}
}
正規表現の記述の違いによってMapフェーズでのパフォーマンスに差が出る可能性もあるため、大規模なデータを解析する際などには、regex項目についてパフォーマンステストを行い、より速い正規表現を追求するのもよいかもしれません。
データ全体を可視化する
前項で示したもっともシンプルなJSON形式の設定ファイルでDunkheadを実行します。ここではHadoopのスタンドアロンモードでの例を示します。
DunkheadはHadoopアプリケーションなので、WordCountなどと同様、hadoopコマンドなどを利用して、Hadoopの各jarファイルにクラスパスを通した状態で起動する必要があります。引数の定義は以下のようになっており、「入力データが置かれているパス(ディレクトリ)」「出力先のパス(ディレクトリ)」「設定ファイルのパス(ファイル名)」の3つの引数が必要となります。
net.jumperz.app.dunkhead.Main input-path output-path conf-path
メインのクラス名はnet.jumperz.app.dunkhead.Mainです。このクラスはdunkhead.jarファイル内で明示されているため、Hadoopのjarオプションにdunkhead.jarを渡すだけでOKです。
Hadoopをインストールしたディレクトリにdunkhead.jarとdunkhead.confを直接置く場合の実行例を示します。入力となるNASAのアクセスログは/hadoop/nasa/以下に置かれているものとします。出力は/tmp/output/に行います(実行前に/tmp/output/が存在しているとエラーになるので、必ず削除しておく必要があります)。
bin/hadoop jar dunkhead.jar /hadoop/nasa/ /tmp/output/ dunkhead.conf
処理が正常に終了すると、/tmp/output/以下にAll_count.gifという画像ファイルが生成されます。これがDunkheadの出力です。
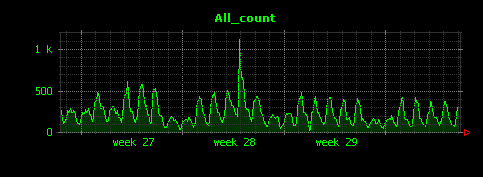
縦軸の単位は5分ごとの平均アクセス数(HTTPリクエスト数)です。今回のデータは約一ヶ月間のもので、平日と思われる日とそれ以外でアクセス数の合計にやや差がありそうなことや、2週目に突発的なアクセス増があったことなどが読み取れます。
このように、190万行という直接エディタで観察するには辛い規模のデータであっても、一目で概要が掴めるようになるのが可視化の威力です。Dunkheadはこの例のように、最低限のタイムスタンプのパースの設定だけを行うと、単純にデータの各行について、時系列の件数のグラフを出力します。
ステータスコード404について注目して可視化を行う
前項では最低限の設定でDunkheadを動作させ、単純なアクセス件数の推移をグラフに出力しました。しかし、ログファイルにはこのグラフからは読み取れる以外にも、さまざまな情報が記録されています。
そこで、次にステータスコードに注目してみることにします。例として、ステータスコードが404(Not Found)となったアクセスについて可視化してみます。
dd15-062.compuserve.com - - [01/Jul/1995:00:01:12 -0400] "GET /news/sci.space.shuttle/archive/sci-space-shuttle-22-apr-1995-40.txt HTTP/1.0" 404 -
404となったアクセスは、上の例のように記録されています。ステータスコードは右から2番目の項目として記録されています。他の項目とは半角スペースで区切られていて、左にはリクエスト行がダブルクォートで囲まれた状態で記録され、右側にはレスポンスサイズが記録されます(この例のようにハイフンの場合もあります)。
設定ファイル(dunkhead.conf)にfields項目を追加します。fields項目の内容はリストである必要があります。今回は404のアクセスを意味するfieldを定義します。設定ファイルの内容は以下のようになります。
{
"datetime": {
"format": " [dd/MMM/yyyy:HH:mm:ss Z] ",
"regex": " \\[.{26}\\] "
},
"fields": [
{
"name": "Status-Code-404",
"regex": "HTTP/1\\.[01]{1}\" 404 [-0-9]+$",
"type": "count"
}
]
}
nameには名前を指定します。今回は単純に「Status-Code-404」とします。regexはこのfieldのデータに対するマッチングを指定する正規表現です。今回このfieldが探すのは404となっている行だけです。例えばログの右側が「HTTP/1.0" 404 -」や「HTTP/1.1" 404 12345」のようになっている行にマッチさせたいので、上記のような正規表現にします。また、typeには「マッチした行の数をグラフ化する」という意味の「count」を指定します。すると生成される画像は以下のようになります(前項同様にAll_count.gifも出力されます)。
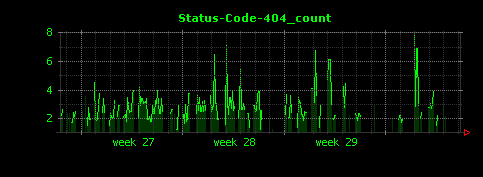
縦軸の値が最大で8程度と小さい値になっていますが、これは5分間あたりの平均として、404のデータがそれほど存在していないことが原因です。Dunkheadでは単位時間あたりの該当行数が少ない場合には、このグラフのようにギザギザした出力が行われることがありますが、これは単位時間をより長く変更することで改善することが可能です(後述)。
このように、fields項目を定義することにより、特定の値(今回はステータスコード404)などに注目してグラフを描画することが可能となります。
すべてのステータスコードについて可視化する
前項では404のみに注目して可視化を行いましたが、他のステータスコードについても可視化を行いたいと考えるのが自然です。下記のように他のステータスコード(例として200と500)についてもfieldを設定することもできますが、
{
"datetime": {
"format": " [dd/MMM/yyyy:HH:mm:ss Z] ",
"regex": " \\[.{26}\\] "
},
"fields": [
{
"name": "Status-Code-404",
"regex": "HTTP/1\\.[01]{1}\" 404 [-0-9]+$",
"type": "count"
},
{
"name": "Status-Code-200",
"regex": "HTTP/1\\.[01]{1}\" 200 [-0-9]+$",
"type": "count"
},
{
"name": "Status-Code-500",
"regex": "HTTP/1\\.[01]{1}\" 500 [-0-9]+$",
"type": "count"
}
]
}
これではやや冗長すぎます。このような場合、以下のように記述することができます。
{
"datetime": {
"format": " [dd/MMM/yyyy:HH:mm:ss Z] ",
"regex": " \\[.{26}\\] "
},
"fields": [
{
"name": "Status-Code-$1",
"regex": "HTTP/1\\.[01]{1}\" ([0-9]{3}) [-0-9]+$",
"type": "count"
}
]
}
太字で記した部分がポイントになります。データ中のステータスコードに当たる部分が、regexの([0-9]{3})の部分です。単に[0-9]{3}と書くのではなく、()で囲んで([0-9]{3})とする必要があります。
nameはStatus-Code-$1とします。$1というのは正規表現において使われる、マッチング結果のグループを意味します。この例のようにregexにおいて()を使ってグループを指定しておき、それをname内で使用することができます。
Dunkheadを実行すると8つの画像が生成されます。1つは全体のアクセス状況を示すAll_count.gifで、他の7つはそれぞれステータスコード200、302、304、403、404、500、501の件数を示すグラフになります。
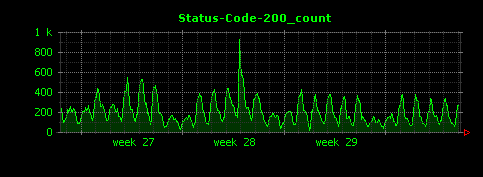
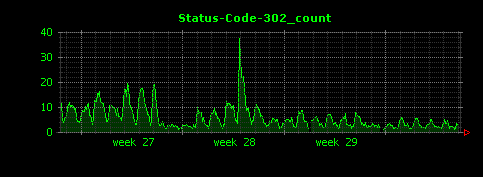
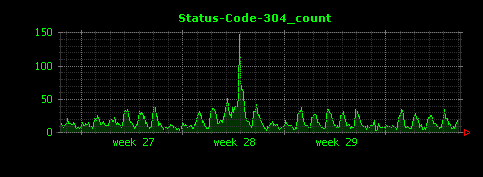
403、500、501については該当するデータの件数が少ないため、Dunkheadデフォルトの「5分ごとの平均値」としてしまうと値が小さくなりすぎてしまうことから、うまくグラフでデータが表現されていません。逆説的ではありますが、このこと(グラフがうまく描画されていないこと)から、ステータスコード403や500、501となったアクセスは、今回のデータ全体に対する比率が非常に小さい、ということが読み取れます。Dunkheadはあくまでデータ解析の最初の手がかりを得ることを目的としたソフトウェアなので、ステータスコード403や500、501のデータについては、ある意味では、これで十分な結果(詳細なデータ解析への入り口)が得られたと考えることもできます。
単位時間を変更する
Dunkheadは内部でRRD(Round Robin Database)を使っています。実装はRRDTools互換であるJava実装のJRobinというライブラリです。RRDToolsにはstepとheartbeatという概念が存在し、これらはDunkheadではデフォルトでそれぞれ5分、10分(300秒、600秒)となっています。前項のグラフから分かるように、ステータスコード403、404、500、501のデータについては5分間の平均値が0〜8程度と低い値になっており、うまく描画されていません。そこで単位時間をもう少し長めに取ってみることにします。
dunkhead.confにrrd項目を追加し、下記のようにstepとheartbeatを指定します。それぞれデフォルトの50倍の値としてみます。
{
"rrd" :
{
"step" : 15000,
"heartbeat" : 30000
},
"datetime": {
"format": " [dd/MMM/yyyy:HH:mm:ss Z] ",
"regex": " \\[.{26}\\] "
},
"fields": [
{
"name": "Status-Code-$1",
"regex": "HTTP/1\\.[01]{1}\" ([0-9]{3}) [-0-9]+$",
"type": "count"
}
]
}
すると下記のように、ステータスコード403と404については、グラフがわかりやすい表示となります。
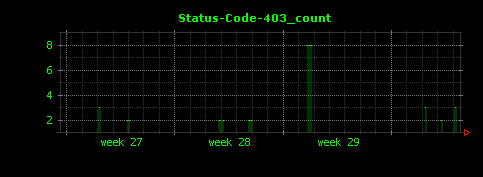
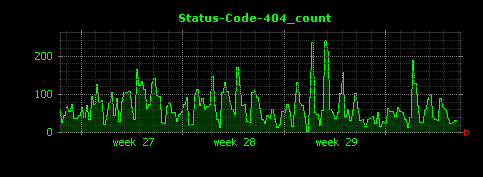
ステータスコード500と501については単位時間を変更してもうまくグラフを描画することは難しく、別途MapReduceのコードを書くか、grep等のアプローチを採って解析していく必要がありそうです。
うまく可視化されないデータを無視する
前項で示したステータスコード500や501のデータのように、数が少なすぎる項目については、Dunkheadの時系列での可視化機能は向いていません。このような項目については閾値を設けて無視することができます。これは、より大量の項目について可視化していく際には、ノイズ(うまく描画されない画像ファイル)を減らすという意味で必須の機能となります。
次のように、threshold項目によって、画像を生成するために最低限必要となるレコード数の閾値を指定することができます。
{
"threshold" : 100,
"rrd" :
{
"step" : 15000,
"heartbeat" : 30000
},
"datetime": {
"format": " [dd/MMM/yyyy:HH:mm:ss Z] ",
"regex": " \\[.{26}\\] "
},
"fields": [
{
"name": "Status-Code-$1",
"regex": "HTTP/1\\.[01]{1}\" ([0-9]{3}) [-0-9]+$",
"type": "count"
}
]
}
今回解析対象に選んだNASAのアクセスログでは、ステータスコード403のレコード数が54、500のレコード数は62、501のレコード数が14です。そのためthresholdを100に設定した場合、これら3つについては無視され、画像ファイルは生成されません。
HTTPメソッド別のアクセス状況を可視化する
次に、GETやPOSTなどの、HTTPメソッド別のアクセス状況を可視化します。
dal31.pic.net - - [01/Jul/1995:00:19:45 -0400] "GET /images/NASA-logosmall.gif HTTP/1.0" 200 786 ppp6.cpbx.net - - [01/Jul/1995:00:19:45 -0400] "HEAD /software/winvn/winvn.html HTTP/1.0" 200 0 slip-5.io.com - - [01/Jul/1995:00:19:46 -0400] "GET /history/apollo/as-201/news/ HTTP/1.0" 200 368 traitor.demon.co.uk - - [01/Jul/1995:00:19:50 -0400] "GET /history/apollo/apollo-13/sounds/ HTTP/1.0" 200 1157 traitor.demon.co.uk - - [01/Jul/1995:00:19:51 -0400] "GET /icons/sound.xbm HTTP/1.0" 200 530
上記のように、メソッドはダブルクォートに続いて大文字のアルファベットが数文字あり、さらに半角スペースが続くという特徴を持ちます。そこで、設定ファイルは以下のように記述します。
{
"rrd" :
{
"step" : 6000,
"heartbeat" : 12000
},
"datetime": {
"format": " [dd/MMM/yyyy:HH:mm:ss Z] ",
"regex": " \\[.{26}\\] "
},
"fields": [
{
"name": "HTTP-Method-$1",
"regex": "\"([A-Z]{1,9}) ",
"type": "count"
}
]
}
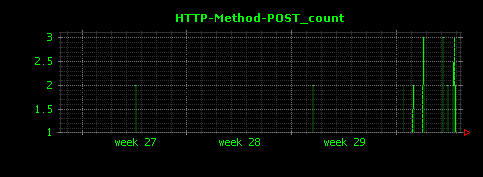
Dunkheadを実行すると、次のようにHTTPメソッド別のアクセス状況が可視化されます。GETが大部分を占め、POSTは殆ど行われていないことがわかります。
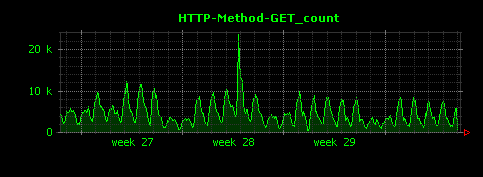
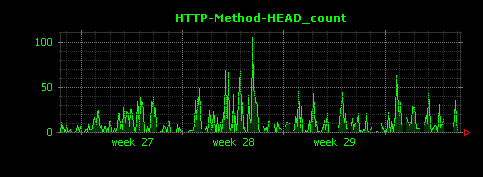
ファイル種別ごとのアクセス状況を可視化する
次に、「.html」や「.gif」のような拡張子に注目し、ファイル種別ごとに可視化を行ってみます。
199.120.110.21 - - [01/Jul/1995:00:00:09 -0400] "GET /shuttle/missions/sts-73/mission-sts-73.html HTTP/1.0" 200 4085 burger.letters.com - - [01/Jul/1995:00:00:11 -0400] "GET /shuttle/countdown/liftoff.html HTTP/1.0" 304 0 199.120.110.21 - - [01/Jul/1995:00:00:11 -0400] "GET /shuttle/missions/sts-73/sts-73-patch-small.gif HTTP/1.0" 200 4179 burger.letters.com - - [01/Jul/1995:00:00:12 -0400] "GET /images/NASA-logosmall.gif HTTP/1.0" 304 0
拡張子は上記のように「HTTP/1.0」のようなHTTPバージョンの左側に位置しているので、正規表現は下記のようにしてみます。ドットに続いてアルファベットが2文字以上、5文字以下続いている部分を拡張子とみなします(URIにクエリパラメータが存在する場合は、今回は無視します)。
{
"threshold" : 100,
"datetime": {
"format": " [dd/MMM/yyyy:HH:mm:ss Z] ",
"regex": " \\[.{26}\\] "
},
"fields": [
{
"name": "File-Type-$1",
"regex": "\\.([a-zA-Z]{2,5}) HTTP/1\\.[01]{1}\" ",
"type": "count"
}
]
}
Dunkheadを実行すると、gif、html、jpgの他、意外な拡張子としてmpgについて、下記のように綺麗なグラフが出力されます。
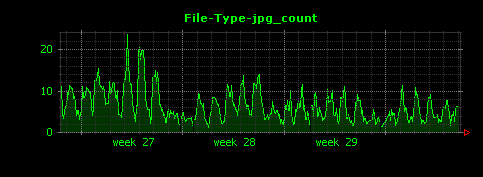
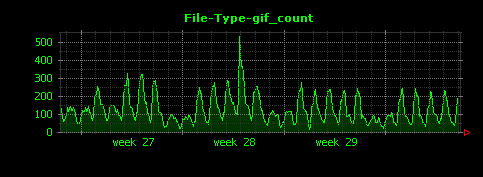
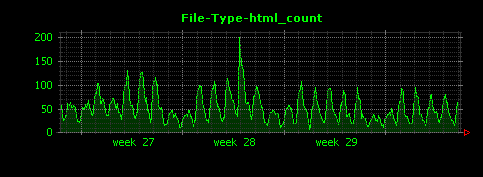
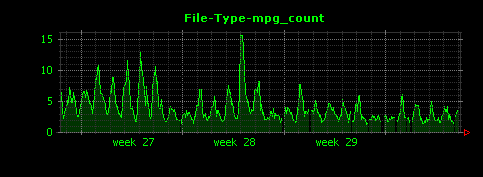
グラフ左側の縦軸の値から、このサイトはgifファイルが非常に多いということがわかります。また、2週目にアクセスのピークが存在していますが、このときjpgファイルへのアクセスは特に増えていないこともわかります。
HTTPレスポンスのサイズについて可視化する
次にHTTPレスポンスのサイズについての可視化を行ってみます。これまでの例ではすべて「該当するデータの単位時間あたりのレコード件数」について可視化してきましたが、今回はデータに含まれる数値(HTTPレスポンスのサイズ)について、単位時間当たりの平均値などについて可視化してみます。HTTPレスポンスのサイズは下記のように、解析対象のログの一番右側に記録されている数値です。
ix-sd11-26.ix.netcom.com - - [01/Jul/1995:00:07:52 -0400] "GET /shuttle/countdown/count.gif HTTP/1.0" 200 40310 ppp-mia-53.shadow.net - - [01/Jul/1995:00:07:53 -0400] "GET /shuttle/missions/sts-71/sts-71-patch-small.gif HTTP/1.0" 200 12054 dnet018.sat.texas.net - - [01/Jul/1995:00:07:56 -0400] "GET /images/NASA-logosmall.gif HTTP/1.0" 200 786 slip1.yab.com - - [01/Jul/1995:00:07:57 -0400] "GET /history/skylab/skylab-2.html HTTP/1.0" 200 1708 dnet018.sat.texas.net - - [01/Jul/1995:00:07:59 -0400] "GET /images/MOSAIC-logosmall.gif HTTP/1.0" 200 363
設定ファイルは下記のようになります。半角スペースによって区切られた一番右の数値を取得するため、regexの値を「 ([0-9]+)$」とします。また、これまでの例ではtypeの値はすべて「count」でしたが、今回はデータ中の値について「単位時間あたりの平均値」を可視化するために、値を「average」とします。
{
"datetime": {
"format": " [dd/MMM/yyyy:HH:mm:ss Z] ",
"regex": " \\[.{26}\\] "
},
"fields": [
{
"name": "HTTP-Response-Size",
"regex": " ([0-9]+)$",
"type": "average"
}
]
}
すると、次のように時系列でのHTTPレスポンスサイズが可視化されます。平均して20KByte前後のレスポンスを返すウェブサイトであるということがわかります。
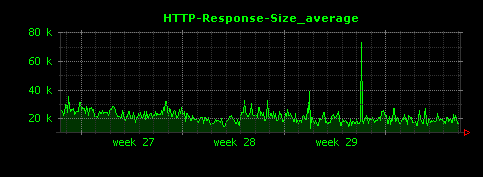
続いて、HTTPレスポンスサイズについて、単位時間あたりの最大値と最小値についても同じように可視化してみます。設定ファイルは以下のように記述します。
{
"datetime": {
"format": " [dd/MMM/yyyy:HH:mm:ss Z] ",
"regex": " \\[.{26}\\] "
},
"fields": [
{
"name": "HTTP-Response-Size",
"regex": " ([0-9]+)$",
"type": "average"
},
{
"name": "HTTP-Response-Size",
"regex": " ([0-9]+)$",
"type": "max"
},
{
"name": "HTTP-Response-Size",
"regex": " ([0-9]+)$",
"type": "min"
}
]
}
HTTPレスポンスサイズの単位時間当たりの最大値・最小値は次のように可視化されます。
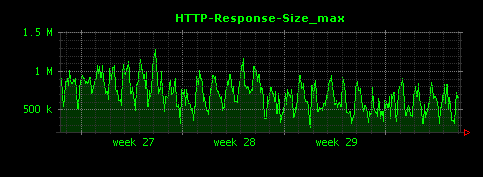
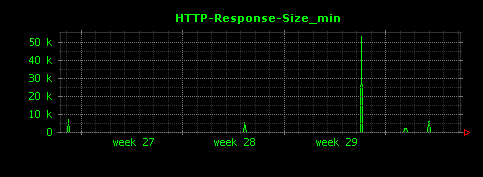
最大値は500KByteから1MByteと、1995年当時にしては結構大きなレスポンスが多いことがわかります。最小値はほとんどゼロですが、これはステータスコードが304の場合にレスポンスサイズ(ボディ部)が0バイトであることが原因であると考えられます。
ファイル種別ごとのHTTPレスポンスサイズを可視化する
前項ではすべてのアクセスを対象にHTTPレスポンスサイズを可視化しました。しかし、画像ファイルとHTMLファイルのように明らかに異なる種類のレスポンスサイズを一緒に可視化しても、あまり意味がありません。そこで次に、ファイル種別ごとに分けた形でHTTPレスポンスサイズを可視化してみます。設定ファイルを次のようにします。
{
"rrd" :
{
"step" : 900,
"heartbeat" : 1800
},
"datetime": {
"format": " [dd/MMM/yyyy:HH:mm:ss Z] ",
"regex": " \\[.{26}\\] "
},
"fields": [
{
"name": "HTTP-Response-Size-$1",
"regex": "\\.([a-zA-Z]{2,5}) HTTP/1\\.[01]{1}\".* ([0-9]+)$",
"type": "average",
"eval" : "$2"
}
]
}
今回、はじめてevalという項目が登場しています。evalは、解析対象のデータ(行)からどのように数値を取り出すかを、より高い自由度の元で指定するために使います。
regex項目において、()で囲まれている部分(グループ化されている部分)が2箇所あります。ひとつめは[a-zA-Z]{2,5}で、これによって拡張子を取得します。ふたつめは[0-9]+で、これによってHTTPレスポンスのサイズを取得します。
ひとつめ(拡張子)はnameの中で使用しており、nameの値であるHTTP-Response-Size-$1のうちの「$1」の部分がこれに当たります。name項目はMapReduce処理においてキーとして使われます。今回は、例えば「HTTP-Response-Size-gif」や「HTTP-Response-Size-html」などのキーが生成されることになります(より正確には、さらに「_average」や「_max」などが付加された文字列がキーとなります)。
ふたつめ(HTTPレスポンスサイズ)が、今回データを可視化するために実際に使われる「数値」(縦軸の値)となります。eval項目はこのようにregex項目に複数のグループが存在する場合や、データに含まれる数値について事前に何かしら計算を行いたい場合に使います。今回はregexの中の2つめの()で囲まれた部分(グループ)が可視化するためのデータの数値であるため、evalの値が「$2」となるわけです。
これによって、下記のように、ファイル種別ごとに、HTTPレスポンスサイズの単位時間あたりの平均値が可視化されます。
上記設定ファイルを使ってDunkheadを実行すると、50個ほどの画像ファイルが生成されますが、ここでは比較的きれいなグラフになっているものを選んで掲載しています。
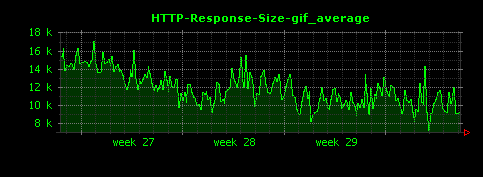
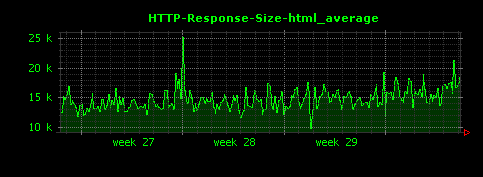
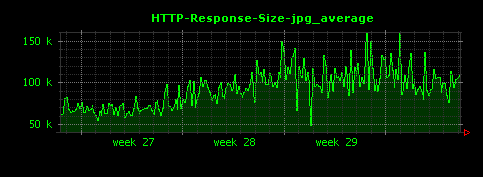
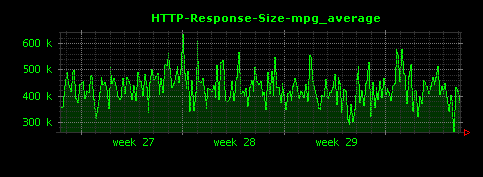
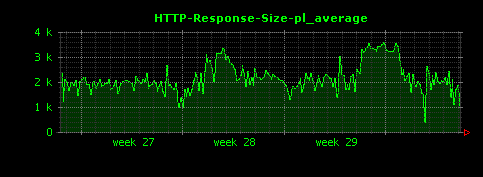
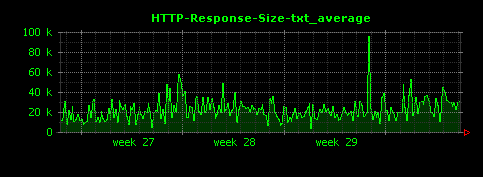
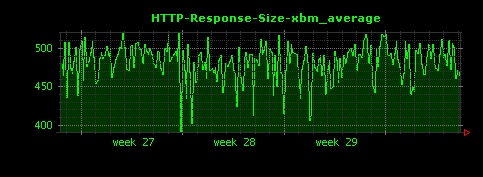
gif、htmlについては10〜15KB前後、jpgはそれよりはやや大きめで100KB前後、mpgはさらに大きく400KB前後がレスポンスサイズの平均値であることがわかります。また、xbmという拡張子で450バイトほどのレスポンスを返すアクセスが存在していることもわかります。
上記は平均値(average)でしたが、次に最大値(max)を可視化してみます。設定ファイルを次のように書き換えます。
{
"rrd" :
{
"step" : 900,
"heartbeat" : 1800
},
"datetime": {
"format": " [dd/MMM/yyyy:HH:mm:ss Z] ",
"regex": " \\[.{26}\\] "
},
"fields": [
{
"name": "HTTP-Response-Size-$1",
"regex": "\\.([a-zA-Z]{2,5}) HTTP/1\\.[01]{1}\".* ([0-9]+)$",
"type": "max",
"eval" : "$2"
}
]
}
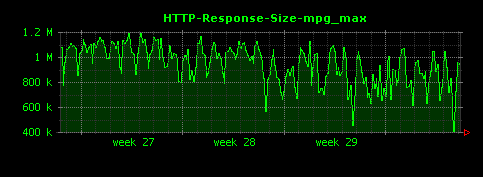
HTTPレスポンスのファイル種別ごとの最大値は、次のように可視化されます。
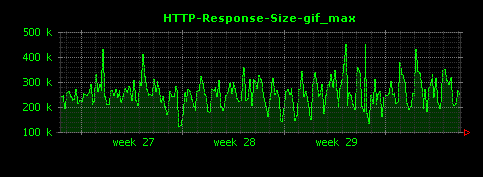
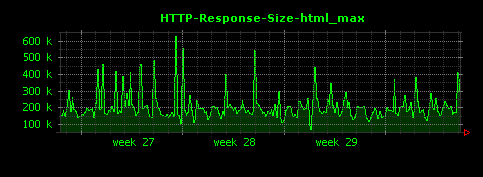
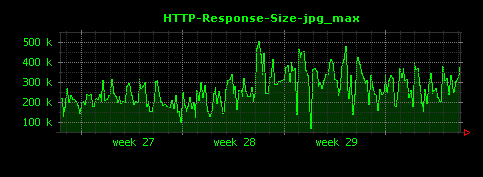
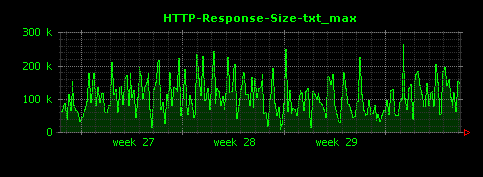
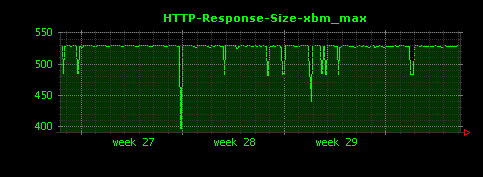
gifは、平均値は15KB程度でしたが、最大値は300〜400KBと、比較的大きい画像が存在していることがわかります。htmlについても同様に、最大のものは600KBを超える大きなもの(平均値の約20倍)が存在することがわかります。
mpgファイルは最も大きなもので1.2MB程度あるようです。また、xbmについては530バイトほどのレスポンスに対して安定したアクセスが発生している様子がわかります。
コンテンツ別のアクセス状況を可視化する
次に、コンテンツ別(URI別)のアクセス状況を可視化します。単純にURI部分をキーにしてDunkheadを出力してしまうと、ログファイル中に存在するURIの種類と同数の、大量の画像ファイルが生成されてしまいます。そこで、今回はURIの末尾が「html」となっているURIで、かつthresholdを2000に設定して実行してみます。
{
"threshold" : 2000,
"rrd" :
{
"step" : 6000,
"heartbeat" : 12000
},
"datetime": {
"format": " [dd/MMM/yyyy:HH:mm:ss Z] ",
"regex": " \\[.{26}\\] "
},
"fields": [
{
"name": "$1",
"regex": "\"[A-Z]{1,9} /([^ ]+html) ",
"type": "count"
}
]
}
この内容でDunkheadを実行すると、約35個の画像ファイルが生成されます。ここでは下記3つの画像ファイルに注目してみます。
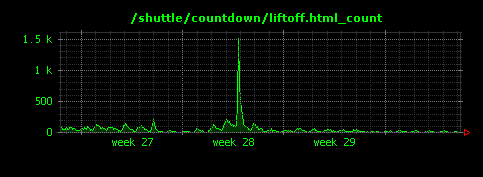
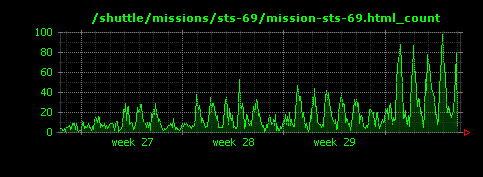
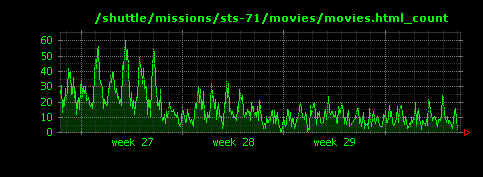
1つめの画像は/shuttle/countdown/liftoff.htmlへのアクセス状況を可視化したものです。2週目のピーク時にアクセスが集中していますが、URLから、おそらくスペースシャトルの打ち上げの模様を中継したのではないかと考えられます。一方で、他の2つのURLへのアクセスには特にシャトル打ち上げのタイミングではピークがなく、この一ヶ月の間に、それぞれ徐々にアクセスが増えたり、減ったりしていることがわかります。
期間別(日別)のアクセス状況を可視化する
今回の解析対象であるNASAのアクセスログは、ちょうど一ヶ月分のものです。このデータ全体の期間が、解析する対象として長すぎる場合があります。そのような場合、もちろんDunkheadを実行する前にgrep等で対象の期間のみをデータから切り出すというアプローチも考えられますが、次のようにregex項目においてタイムスタンプ部分をグループ化することで、それぞれの期間ごとに分けた可視化を行うことができます。
199.72.81.55 - - [01/Jul/1995:00:01:51 -0400] "GET /images/USA-logosmall.gif HTTP/1.0" 200 234 gater4.sematech.org - - [01/Jul/1995:00:01:52 -0400] "GET /images/NASA-logosmall.gif HTTP/1.0" 200 786 199.72.81.55 - - [01/Jul/1995:00:01:52 -0400] "GET /images/WORLD-logosmall.gif HTTP/1.0" 200 669 ix-or10-06.ix.netcom.com - - [01/Jul/1995:00:01:52 -0400] "GET /software/winvn/userguide/wvnguide.html HTTP/1.0" 200 5998 gater3.sematech.org - - [01/Jul/1995:00:01:52 -0400] "GET /images/KSC-logosmall.gif HTTP/1.0" 200 1204
今回は日別にデータを分けてみます。上記のようにデータのうち「01/Jul/1995」のような部分が日を表しているので、設定ファイルを以下のように記述します。値は単純に、日別のアクセス数(HTTPリクエスト数)とします。
{
"datetime": {
"format": " [dd/MMM/yyyy:HH:mm:ss Z] ",
"regex": " \\[.{26}\\] "
},
"fields": [
{
"name": "$1",
"regex": " \\[([0-9]{2}/[a-zA-Z]{3}/[0-9]{4}):",
"type": "count"
}
]
}
Dunkheadを実行すると、約30個ほどの画像ファイルが生成されます。ここでは、シャトル打ち上げの前後と思われる3日間のデータを示します。
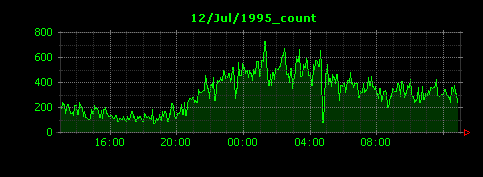
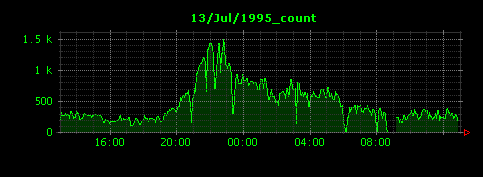
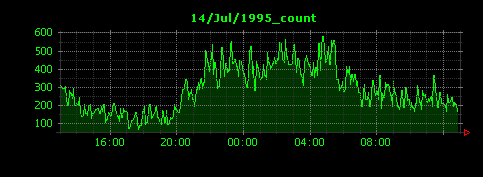
13日のアクセスは(日本時間の)午後22時頃にピークを迎え、5分間の平均HTTPリクエスト数は約1500に達していたことがわかります。前日の12日や次の14日はピーク時でも500〜600程度に落ち着いています。13日は断続的にグラフに谷間が存在していますが、もしかしたらここでウェブサーバが落ちていたのかもしれません。
まとめ
今回は、Hadoop上で手軽にデータを可視化するためのソフトウェア、Dunkheadを使い、NASAの1995年のウェブサーバのアクセスログを解析してみました。Dunkheadを使うと、grepか、あるいはegrepを行うような気軽さ(簡単な設定ファイルの記述のみ)で、さまざまな視点からデータを可視化できるようになります。
今回はエンジニアの方にはなじみ深いウェブサーバのアクセスログを題材にしてみました。正直なところ、ウェブサーバのログ解析に関しては既に専用のソフトウェアがたくさん存在している状態であり、Dunkheadがそれらに比べて特別に大きなメリットを持っているかというと、そうではありません。例えば、「アクセス数の多いURLの上位10個」を知りたい場合、Dunkheadの可視化はあまり有効に機能しません。
Dunkheadの大きなメリットは、Hadoop上で動作するため、ログファイルのサイズが非常に大きい場合(数百GB,あるいはそれ以上)でも使うことができる、という点です。
Dunkheadはウェブサーバのアクセスログに限らず、タイムスタンプが付いているログであれば何でも可視化できます。本エントリはウェブサーバのログについてというよりも、むしろDunkheadをどのように設定するとどのような画像が出力されるか、というチュートリアル的な視点で読んでいただければと思います。
Dunkheadは解析の第一歩、はじめの段階で使用することを想定して開発されています。まずデータをざっと可視化して、全体の概要や特徴を掴み、そこからさらに「何を解析するべきか?」を考える。ビッグデータを前にして悩むエンジニアの助けになれば幸いです。フィードバック等はお気軽に@kinyukaまで。