技術者ブログ
クラウド型WAF「Scutum(スキュータム)」の開発者/エンジニアによるブログです。
金床“Kanatoko”をはじめとする株式会社ビットフォレストの技術チームが、“WAFを支える技術”をテーマに幅広く、不定期に更新中!
クラスタリングベースの異常検知アルゴリズムXBOSとは何か
XBOSの概要
XBOS(Cross interaction based outlier score)はクラスタリングを使う教師なし異常検知アルゴリズムです。異常と正常両方を含んだラベルなしのデータセットに対して適用し、それぞれのデータに対して異常度のスコア付けを行う形で使用します。発想も実装も非常にシンプルで、Pythonではわずか55行のコードの実装になっています。Scutumにおけるアノマリ検知のために開発されたもので、こちらの記事で書いたようにかなり良い性能を発揮します。
XBOSの処理は大きく2つのステップに分かれており、まずクラスタリングを行い、次にクラスタ間の調整を行います。
Step1: K-Meansによるクラスタリング
まずはじめにクラスタリングを行います。クラスタリング自体はどのアルゴリズムを使っても問題なく、ScutumではとりあえずK-Meansを使っています。K-Meansを使っているため、パラメータとしてクラスタ数を指定する必要があります。
クラスタリングによって、データがいくつかの塊に分けられ、ざっくりと複数のグループ、データ群に抽象化されます。XBOSでは大きなクラスタに所属するデータは異常度が低く、小さなクラスタに所属するデータは異常度が高いという考え方をします。
世間的には「クラスタリングを行ってから、どのように異常度を考えるか」については様々な手法が存在しており、このようにクラスタ毎にスコアを付ける方法の他に、所属するクラスタの中心からの距離が離れているデータの異常度を高いと考える方法もあります(オライリーのSparkによる実践データ解析の異常検知がこのタイプです)。この辺りをどうするかは自由であり、データと対話しながら適している手法を選択すればよいでしょう。逆に言えば「クラスタリングベースの異常検知」というだけでは具体的にどのようなアルゴリズムなのかは特定できないので、どのように異常度を計算しているのかを知るにはさらに詳細を調べる必要があるということになります。
異常検知でクラスタリングベースのアルゴリズムを用いる際の大きな利点の一つは、大量のデータからバッチで学習させてモデルを作った際に、モデルが軽量になることです。モデルは大量のデータ全てを記憶している必要はなく、クラスタリングの結果、つまりクラスタ中心(centroid)の座標のみを記憶していれば良いので、メモリは殆ど消費しません。そのため学習はバッチ、適用はオンラインというシステムや、Scutumのように大量のサーバにモデルを配布したいシステムに向いています。
逆に大量のデータを一度処理してその中の異常を探すことが目的である場合(バッチで完結する場合)は、k近傍法ベースの手法も試してみるのが良いでしょう。
Step2: クラスタ間の相互作用を計算
先ほど書いたように単純に「大きなクラスタに所属するデータは異常度が低く、小さなクラスタに所属するデータは異常度が高い」とした場合、例えばヒストグラムが以下のようになる一次元のデータではうまく異常度が出ないと考えました。
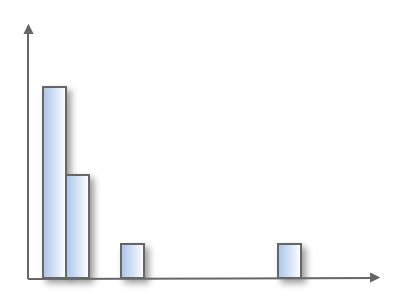
このデータにk=3でクラスタリングを行うと、以下のようにC1〜C3の3つのクラスタに分類されます。
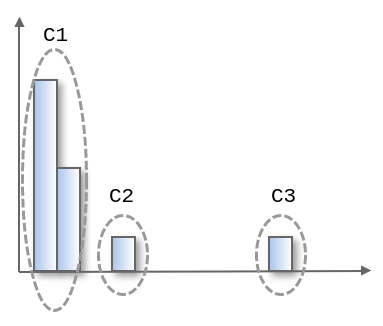
C1は大きく、C2とC3はともに同じサイズで小さくなります。そのため異常検知の視点で考えた場合、ざっくりとした傾向として
- C1に所属するデータは正常
- C2に所属するデータは異常
- C3に所属するデータはC2と同じレベルで異常
ということになります。しかし直感的にヒストグラムから受ける印象としては、C3の方がC2よりも異常であるように思えます。このことを反映するため、クラスタ間の距離を考慮に入れて相互作用を計算することにしました。相互作用のイメージは電球です。
それぞれのクラスタを、光っている電球のように考えてみます。クラスタが大きい(所属するデータの数が多い)ほど明るく、他のクラスタを照らします。小さいクラスタはあまり光っていないので、他のクラスタに及ぼす影響も小さくなります。
他のクラスタを照らす光は距離が離れるほどに作用を失います。そのためC1が放つ光はC2を明るく照らしますが、C3に対してはそれほど影響を与えません。
C2とC3もそれ自身が光りますが、クラスタのサイズが小さいため、この明るさはわずかなものと考えます。そのためC2がC1に及ぼす影響はあまり大きくありません。C2とC3の距離は離れているので、C2がC3に及ぼす影響はほぼゼロとなります。逆のC3からC2への影響も、同じようにほぼゼロとします。
C2はC1によって強く照らされたため、結果的にC3に比べて明るくなった、と考えます。
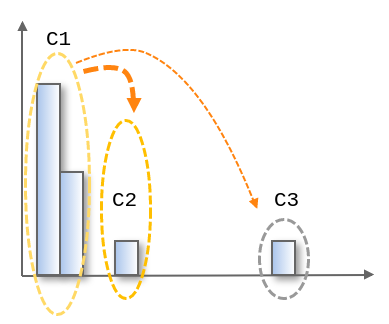
この「明るさ」を正常度(異常度の逆)として考えると、次のようになります。
- C1に所属するデータは正常
- C2に所属するデータもそこそこ正常
- C3に所属するデータは異常
このように各クラスタを電球に見立てて計算した結果、ヒストグラムを見た際に人が受ける直感的な印象を反映した異常度を各クラスタに割り当てることができるようになりました。
クラスタ間の相互作用を実装する段階では結果を見ながら試行錯誤し、この部分のようにしてみました。effectivenessという変数はハイパーパラメータとなっており、クラスタ間の相互作用の強さを調整できるようになっています。
各データの異常度の算出
各特徴について上記のようにStep1のクラスタリングとStep2のクラスタ間の相互作用の計算を行い、クラスタの位置と、それぞれの異常度を決定しておきます。
次に、全てのデータについて異常度のスコアを算出していきます。各データの各特徴について、所属するクラスタがどれになるか、という情報からスコアを求め、全特徴のスコアを掛け合わせることで最終的にそのデータのスコアとします。実際には多数の小数同士の乗算を避けるために対数を取ってから加算にします。ここはHBOSと同じです。
XBOSではスコアの値が小さいほど異常となります。
XBOSの特徴
XBOSはNaive BayesやHBOSと同じように特徴間の相関を完全に無視します。そのためデータによっては非常に性能が悪くなる可能性があります。一方で結果を解釈しやすいメリットがあります。
- 各特徴においてどのようなクラスタが形成されたか
- クラスタ間相互作用の計算の結果、どのクラスタにどの程度の異常度が割り当てられたか
- あるデータの異常度はどのように計算されたか
を全て追えるので、意図しない結果が出た場合や、より精度を上げていきたい場合(特徴を選んだり重み付けを変えたい場合など)に正しい方向に変化させることができます。
XBOSの実装
XBOSにはPythonとJavaの2つの実装が存在します。
Python版はGitHubでオープンソースで公開しています。使用例はこちら。
Java版は実際にScutumで使っているものです。現時点ではソースコードは公開していませんが、これはまだ単にソースコードを整理できていないというのが理由です。Java版は1次元のデータに特化したK-Means実装も含んでいて、非常に高速です。もしニーズがあるようであれば整理して公開しますので、お声がけください。
XBOSの生い立ち
こちらの記事に書いたように、XBOSはScutumのアノマリ検知機能の開発において試行錯誤の中から生まれたものでした。最初は名前を付けたり公開したりする予定はなかったのですが、最近になり後追いで異常検知について勉強し調査してみたところ、そこそこ性能が良いことが見えてきたのでこのような記事を書いています。
個人的には特徴間の相関を完全に無視するというアプローチは今時のデータサイエンスの進化に完全に逆行しているように感じていました。「コンピュータとソフトウェアの進化によって人間には見つけることができないような多数の特徴間の複雑な関係が計算可能となり、その結果識別性能を上げることが可能になった」ということこそが近年のデータサイエンスの成果だと思っていたからです。
しかしいざデータを目の前にした時、特に教師なし学習であったため、「とりあえずはシンプルなアプローチから始めよう」と考えて各次元別に処理を進めていきました。このようにすることで、思わぬ結果が出た場合でも「どの特徴で、本来異常なのに正常と判断したか?」などがわかるので、生のデータを見て原因を調べることができました。
その後HBOSを知ったときに「おお、特徴間の相関を無視しているアルゴリズムも普通にあって、しかも結構性能が良いのか!」という驚きとともに、自分が考えたXBOSもとりあえずは恥ずかしくないアルゴリズムなのかもしれない、と考えました。(よく知っているつもりだったNaive Bayesも特徴間の相関を無視していたのに、まったくそれにも気づけていませんでした...)
HBOSを参考にXBOSという名前にし、かつ小数同士が何度も乗算される問題を避けるテクニックもHBOSから真似させてもらい、現状のようなアルゴリズムにしました。
まとめ
今回はScutumの開発の中で試行錯誤から生まれた異常検知アルゴリズム、XBOSについてまとめました。Pythonの実装は手軽に試せるようになっていますので、是非試してみてください。フィードバックはお気軽に@kinyukaまで。