技術者ブログ
クラウド型WAF「Scutum(スキュータム)」の開発者/エンジニアによるブログです。
金床“Kanatoko”をはじめとする株式会社ビットフォレストの技術チームが、“WAFを支える技術”をテーマに幅広く、不定期に更新中!
Kaggleクレジットカード詐欺データセットで3種の異常検知アルゴリズムを比較
はじめに
Scutumでは2017年の初旬からアノマリ検知(異常検知)による防御機能の開発を本格的にスタートし、1年ほどかけて徐々に実用性を高めてきました。ここで行っているのはいわゆる「教師なし学習による異常検知」で、中核としているアルゴリズムはXBOSというものです。
しばらくの間は完全に手探りでシステム開発を進めていて、異常検出のアルゴリズムの定量的な性能については科学的な裏付けに乏しい状態でした。「なんとなく動いている(異常を見つけることができている)ようだから、これでいいか」という感じの状態でデプロイし、結果を見て改善を重ねるというサイクルを繰り返してきた形です。
2018年になり、これまで殆ど目を通すことができていなかった異常検知に関する学術的な情報(論文等)を見ていたところ、いくつか面白い発見がありました。そこで今回、少し自分でも手を動かして調査したポイントのうちの1つ、3つの異常検知アルゴリズムの性能比較をこの記事にまとめてみました。
どんなデータセットか
比較に使ったKaggleクレジットカード詐欺データセットは2013年9月のヨーロッパにおけるクレジットカードのトランザクションデータです。2日間に発生した約28万のトランザクションには492件の詐欺が含まれています。詐欺は全体の0.172%と割合としては非常に少なく、いかにも異常検知向けのデータセットと言えるでしょう。全体で28万というデータ量は少な過ぎず、かつ今時のコンピュータならば1台でそこそこ手軽に試すことができる、ちょうどよい量だと思います。
データは28次元の特徴ベクトルとして使います。これはPCA(主成分分析)された後のものとなっています。PCAの具体的なパラメータや変換前の特徴が何次元だったのか、またそれらの意味などは全て不明となっており、純粋にデータの中身、数値そのものを見ていくアプローチとなります。
データにはラベルが付けられており、どの492件が詐欺なのかはわかる状態です。そのため教師有り学習に使うことも可能ですが、今回はラベルの情報を削除し、教師なしの異常検知(Unsupervised Anomaly Detection)を行ってみました。モデルが生成され、データに対する異常度のスコア付けが完了した後に、性能評価のみのためにラベルの情報を使います。
何を目的とするか
今回は教師なしの異常検知アルゴリズムを3つ(XBOS、HBOS、Isolation Forest)選び、それぞれどの程度の詐欺を見つけることができるのかを計測し、比較します。本来のデータサイエンスであれば評価を開始する前に目標とする数値(詐欺検出性能)のようなものがあって然るべきかもしれませんが、今回は相互比較を目的とします。
何故比較するのか
筆者はデータサイエンスや異常検知の専門家ではなく、Scutumのアノマリ検知機能の開発は異常検知の知識なしに開始した背景があります。具体的な例として、開発を開始した当初はIsolation ForestやHBOSといったアルゴリズムのことはまったく知りませんでした。HBOSは(少なくとも日本国内では)それほど知られていないと思いますが、Isolation Forestはそこそこ有名なアルゴリズムであり、異常検知をしようとする人であれば少なくとも名前くらいはきいたことがあると思います。
当初、何も知らない状態からスクラッチでとりあえずそれっぽいアルゴリズム(XBOSという名前を後付けしました)を作ってみたところ、とりあえず結果としては異常が発見できている様子だったのでそのまま進めていたのですが、その間ずっと「このような科学的な裏付けのないアルゴリズムを作って使うような、独りよがりな状態はまずいか...?」という疑念がありました。そこでこれを解決し、さらにより良いアルゴリズムがあればそれに乗り換えようと考え、いくつかの既知のアルゴリズムと比較することにしました。
どのアルゴリズムを比較するか
今回の目的で教師なしの異常検知に使えるアルゴリズムや実装はそれほど豊富には存在しておらず、Scutumで使用しているXBOS、そしてscikit-learnでも使えることから良く知られているIsolation Forestと、こちらの非常に良質な教師なし異常検知に関する研究レポートで高い評価となっているHBOSの3つを選択しました。
他に有名な異常検知アルゴリズムとしてLOF(Local Outlier Factor)がありますが、これは今回の目的(LocalではなくGlobalなAnomalyを見つけたい)にはそぐわないため除外しました。(一応動かしましたが、結果は悪かったように記憶しています)
また、LOFと同様にポピュラーなk近傍法を使うアルゴリズムについては、バッチでの学習時に構築したモデルをできるだけ軽量にしてランタイム(WAF)に載せたい、という我々のニーズを満たせないため、こちらも除外しています。
(LOFやk近傍法を使うアプローチも非常に有力な異常検知アルゴリズムなので、この記事を読まれた方が自身の環境で異常検知をテストする際には、除外せずに試してみることをお勧めします。)
他にはデータの分布として正規分布を仮定するアルゴリズムが多数ありますが、実際には正規分布しているような単純なデータを見かけることは少ない(あるいはそのような状況では、そもそも異常検知に苦労しない)と考え、今回は評価の対象外としています。
どのように比較したか
比較は3つのアルゴリズム全てについてPython実装を用いて行いました。コードやデータはこちらのKaggleカーネルにアップロードしてあるので、追試することが可能です。
約28万のデータそれぞれに対して、各アルゴリズムは異常度のスコアリングを行います。スコアリング後、データを異常度が高いものから順にソートし、「異常度が高いと判定した1000のデータ」を選びます。その1000のうち、実際にラベルが「詐欺」であるものがいくつ存在するか、をわかりやすい指標として選択しました。また、ROC曲線のような形で視覚的にもわかるよう、異常度が高いN個のうち実際に詐欺がいくつ含まれているかを図示し、AUC的な面積の数値も一応データサイエンスっぽく算出しました。
やっていることは本当に単純で、データを各アルゴリズムの実装に食わせ、スコアを出力させてそれを集計しているだけです。難しい部分はすべて実装側に閉じ込めてあるので、評価そのものはすぐに終わりました。
比較結果
XBOSとIsolation Forestは実行毎に少し結果がブレますが、概ね結果は以下のようになりました。
- XBOS: 1000のうち約280が実際の詐欺
- HBOS: 1000のうち約220が実際の詐欺
- Isolation Forest: 1000のうち約220が実際の詐欺
(AUC的な面積の数値についてはKaggleカーネルの出力を参照のこと)
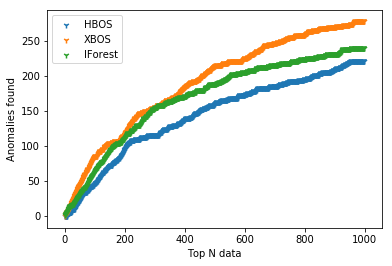
XBOSがスクラッチで考えたアルゴリズムであるにも関わらず圧倒的に良い性能であることが確認され、うれしい驚きでした。このため特に開発中のシステムの内容を変える必要がないこともわかりましたし、チーム内での納得感・安心感も高まりました。
まとめ
今回は3つの教師なし異常検知アルゴリズムを同一のデータセットに適用し、性能を比較しました。HBOSとIsolation Forestは検出性能が拮抗し、またXBOSは他の2つに比べ非常に高い性能を示すことがわかりました。
HBOSについてはこちらの記事、XBOSについてはこちらの記事に詳細をまとめています。
この記事についてのフィードバックはお気軽に@kinyukaまで。