技術者ブログ
クラウド型WAF「Scutum(スキュータム)」の開発者/エンジニアによるブログです。
金床“Kanatoko”をはじめとする株式会社ビットフォレストの技術チームが、“WAFを支える技術”をテーマに幅広く、不定期に更新中!
ヒストグラムベースの異常検知アルゴリズムHBOSとは何か
HBOSの概要
HBOSはヒストグラムベース、統計ベースの教師なし異常検知アルゴリズムです。非常にシンプルでわかりやすく、論文も読みやすいです。ラベルがついていないデータセットに対して適用し、各データについて異常度(Anomaly Score)を算出してくれます。利用者は結果と相談しながらこの異常度に対して閾値を決め、それ以上を異常として扱うような形で使うことができます。こちらの研究レポートでHBOSが速度・検出精度ともに優秀であることが紹介されています。
ヒストグラムベースとはどういうことか
HBOSでは各特徴それぞれについて全データの値からヒストグラムを作成し、それぞれのビン(ヒストグラムのいわゆる縦棒のこと)について、所属するデータの数が多ければそのビンに所属するデータは正常、少ないならば異常という考え方でスコアが付けられます。個人的にはクラスタリングでの異常検知にも近い考え方だと思います。
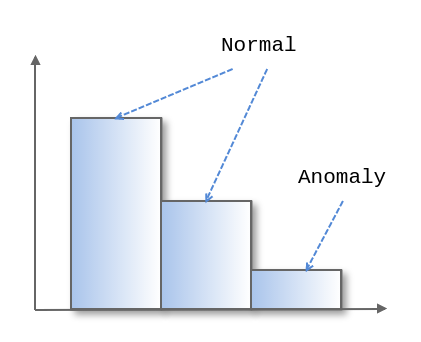
各特徴について上記のように独立にスコアを計算し、最後に、あるデータの全特徴のスコアを乗じます(実際には小数同士の乗算が多数行われる事を避けるため、底が10の対数値に変換し、加算として処理します)。この数値がそのデータの異常度となります。値が高いほど異常となります。
全体をいくつのビンに分けるか、というハイパーパラメータ等が存在します。
HBOSの特徴
HBOSはNaive Bayesのように、特徴間の相関を完全に無視します。そのためデータの性質によってはまったく良い性能を発揮できない可能性があると思います。一方でそれぞれの特徴について個別にスコアが算出されるので、結果の解釈がある程度可能であり、また特徴毎に重みを変えるような応用もしやすいメリットがあります。処理速度が必要な場合は、実装の並列化も容易だと考えられます。
ランダムな値やseed的なものが使われないアルゴリズムであるため、同じデータに対しては毎回必ず同じ値が算出されます。
HBOSの実装
Javaの実装とPythonの実装が利用可能です。どちらもオープンソースです。
HBOSの作者はJava製の商用データマイニングソフトウェアであるRapidMinerに実装を提供しています。アルゴリズム実装部分はGitHubにあり、オープンソースで利用可能になっています。こちらが本家の実装です。このリポジトリにはHBOS以外にも数多くの異常検知が含まれており、Pythonユーザが多く使うScikit-learnには含まれないような多数のアルゴリズムが使用可能になっていてとても魅力的です。
HBOSのPython版は私がアルゴリズムの評価とPythonの練習のために作成したこちらのものと、開発中と思われるPython製ツールキットPyODの2つが存在しています。他にもあるかもしれません。
私はHBOSについて、本当は本家のRapidMinerを使ってすぐに評価したかったのですが、データ数が多い場合はRapidMinerのフリー版では実行できなかったため、アルゴリズムを理解するついでにPythonに移植してみました。
Pythonの初心者であるため「Pythonでは、速度が必要な箇所ではforループを使わず、NumPyを使う」という常識がなく、Java版をほぼそのまま行ごとにPythonに変換しました。そのため処理速度は遅くなっています(移植後にあまりの遅さに気づき、そこから調べて涙しました)。
Python版で大量のデータを処理したい人はNumPyを使うように書き換えるか、諦めてJava版を使っていただければと思います。(Python版、プルリク募集中です)
HBOSはアルゴリズムとしては計算量は多くなく、高速な部類に属します。
私が実装したHBOSはscikit-learnのように、fit_predictを呼ぶだけの簡単な呼び出しで使えるようになっています。
from hbos import HBOS from pandas import DataFrame hbos = HBOS(bin_info_array=[10]) result = hbos.fit_predict(DataFrame(data={'column1':[0,0,0,1,1,1,1,1,1,1,2,2,2,2,3,4,4,5,5,5,5,5,6,6,6,6,6,6,6,6,7,8,8,9,9,9,9,9,9,9,9,9]})) print(result)
まとめ
今回は教師なしの異常検知アルゴリズム、HBOSについて簡単にまとめてみました。日本語での情報が皆無のようでしたので、この記事が少しでもお役に立てば幸いです。この記事についてのフィードバックはお気軽に@kinyukaまで。