技術者ブログ
クラウド型WAF「Scutum(スキュータム)」の開発者/エンジニアによるブログです。
金床“Kanatoko”をはじめとする株式会社ビットフォレストの技術チームが、“WAFを支える技術”をテーマに幅広く、不定期に更新中!
超高速のPostgreSQLとしてGreenplumを気軽に使う
はじめに
ビッグデータ、データサイエンスという言葉の流行を大きく後押ししたのは大規模なスケールアウト、分散処理を可能としたHadoopの存在です。しかしデータサイエンティストは日々のデータ処理作業において必ずしも複数台のマシンを必要とするような大規模な処理ばかり行っているわけではありません。自身の開発用ワークステーション1台で完結するような処理も多数存在します。
2016年ではもはや当たり前ですが、多くのワークステーションはマルチコアのCPUを搭載しており、CPUがボトルネックになるようなデータ処理をマルチコアを活かして並列処理する重要性は高まっています。しかし、意外に多くのソフトウェアが、この当たり前に期待される「マルチコアを活かして単一ワークステーション上で高速並列処理すること」が出来ていません。
この悩みから、筆者は過去にテキストデータ処理を簡単にマルチコア対応にするJavaフレームワーク、MCPを開発してegrepより10倍速い行ベースの正規表現による検索を実装しました。また同様にWEKAのK-Meansクラスタリングをマルチスレッド対応させ、1台のワークステーション上でのクラスタリングを高速化しました。
続いて筆者の頭を悩ませたのは、RDBでのデータ解析です。データを対話的に解析するためにSQLを頻繁に利用しているのですが、メインで使っているPostgreSQLは基本的に1つのクエリは1つのCPUコア上で処理するため、マルチコアのパワーを全く活かせません(RDBではディスクアクセスがボトルネックになることが多いと思われていますが、CPUがボトルネックになるケースも結構あります)。
上記のMCPやWekaとは異なり、RDBのクエリを並列処理させるのはちょっとした開発で行えるような簡単なものではないので、どうしようかと悩んでいました。しかし最近になり、並列処理可能なRDB(MPPデータベースなどと呼ばれる)のうちの一つであるGreenplumがオープンソース化され、誰でも自由に使えるようになりました。
Greenplumを使うことで、マルチコアを全て活かした高速なデータ解析が行えるようになります。
Greenplumとは?
GreenplumはPostgreSQLを元に開発された並列処理可能なRDBです。SQLをごく普通のPostgreSQLと同じ感覚で使うことができる一方で、複数台のマシンに処理を分散し、I/OやCPUリソースをふんだんに使うことができます。開発元であるPivotalのサイトではMassively Parallel Data Warehouseと表現されています。豊富な機能を持つSQLをメインのインターフェースとして利用できるため、Hadoopベースのソフトウェア群よりも取っつきやすく、またSQLをインターフェースとする他のソフトウェアと組み合わせやすいことが期待できます。
元は(おそらく)高価な商用ソフトウェアでしたが、昨年OSS化されることが決定し、現在はGithubから誰にでもアクセスすることができます。
気軽に使える
GreenplumはData Warehouseと表現され、また「テラバイト規模に対応」などと謳っている面もあることから大規模な処理(数十台〜数百台のサーバ)で利用するイメージがあると思いますが、実はちょっとした作業用にも気軽に使えます。コンパイルやインストールはごく簡単で、起動や終了もコマンド一発で完了します。手元の作業用ワークステーションでGreenplumを動かすと、CPUがボトルネックになるようなクエリをきれいにマルチコアを活かして処理してくれるために、PostgreSQLよりも遙かに短時間で結果が返ってくるため感動を覚えます。
簡単なベンチマーク
ウェブのアクセスログの処理を例に、同一のワークステーション上でPostgreSQLとGreenplumの処理速度を比較してみました。
ログをパースしてDBに格納した状態から、それぞれのIPアドレス毎のアクセス数の多い順に30個並べるクエリを発行してみます。
まず、PostgreSQL(9.3.0)です。
sw=# select clientip, count(*) from taccess group by clientip order by count desc limit 30;
clientip | count
-----------------+-------
69.10.137.199 | 66391
208.249.92.135 | 20666
24.69.255.237 | 17638
207.166.200.224 | 16690
205.188.209.43 | 13856
64.213.82.228 | 10275
12.119.251.194 | 9954
64.12.96.198 | 9873
205.188.209.82 | 9685
24.71.223.142 | 9433
68.63.109.213 | 9254
152.163.252.40 | 8444
209.195.134.186 | 8200
24.62.145.72 | 8153
211.28.96.69 | 8076
66.77.127.85 | 7974
69.28.130.230 | 7911
66.151.128.23 | 7873
67.87.47.158 | 7635
152.163.252.196 | 7620
66.185.84.76 | 7607
64.12.96.138 | 7457
130.80.30.75 | 7131
130.80.30.76 | 7034
24.64.223.205 | 6680
198.63.44.241 | 6623
63.99.105.162 | 6598
24.66.94.142 | 6561
24.70.95.205 | 6475
203.97.2.242 | 6113
(30 rows)
Time: 28475.458 ms
28秒かかっています。
次にGreenplum(4.3.99.00)です。今回は1つのワークステーション上に4ノードで構成しています。(使い勝手はPostgreSQLとまったく同じで、クライアントも同じpsqlで、SQLの内容も同一です)
sw=# select clientip, count(*) from taccess group by clientip order by count desc limit 30;
clientip | count
-----------------+-------
69.10.137.199 | 66391
208.249.92.135 | 20666
24.69.255.237 | 17638
207.166.200.224 | 16690
205.188.209.43 | 13856
64.213.82.228 | 10275
12.119.251.194 | 9954
64.12.96.198 | 9873
205.188.209.82 | 9685
24.71.223.142 | 9433
68.63.109.213 | 9254
152.163.252.40 | 8444
209.195.134.186 | 8200
24.62.145.72 | 8153
211.28.96.69 | 8076
66.77.127.85 | 7974
69.28.130.230 | 7911
66.151.128.23 | 7873
67.87.47.158 | 7635
152.163.252.196 | 7620
66.185.84.76 | 7607
64.12.96.138 | 7457
130.80.30.75 | 7131
130.80.30.76 | 7034
24.64.223.205 | 6680
198.63.44.241 | 6623
63.99.105.162 | 6598
24.66.94.142 | 6561
24.70.95.205 | 6475
203.97.2.242 | 6113
(30 rows)
Time: 1867.981 ms
なんと驚くことに2秒かかりませんでした。4ノード構成なので1/4程度の時間で完結することは期待していましたが、まさかの15倍速です。
CPUは以下の画像のように、PostgreSQLでは1コアのみ高負荷になり、Greenplumでは複数コアが高負荷になります。
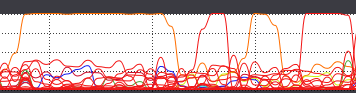
↑PostgreSQL
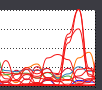
↑Greenplum
えっ?私のPostgres、多すぎ・・・?!
余談ですが、1つのワークステーション上での4ノード構成なので、postgresプロセスが大量になります。psコマンドの結果をpostgresでgrepすると下記のようになります。
gpadmin 12061 0.0 0.6 449976 222836 ? Ss Feb20 0:03 /opt/gp/bin/postgres -D /opt/data1/gpsne0 -p 40000 -b 2 -z 4 --silent-mode=true -i -M mirrorless -C 0 gpadmin 12062 0.0 0.6 449984 222840 ? Ss Feb20 0:03 /opt/gp/bin/postgres -D /opt/data3/gpsne2 -p 40002 -b 4 -z 4 --silent-mode=true -i -M mirrorless -C 2 gpadmin 12063 0.0 0.6 449984 222832 ? Ss Feb20 0:04 /opt/gp/bin/postgres -D /opt/data4/gpsne3 -p 40003 -b 5 -z 4 --silent-mode=true -i -M mirrorless -C 3 gpadmin 12064 0.0 0.6 449984 222844 ? Ss Feb20 0:03 /opt/gp/bin/postgres -D /opt/data2/gpsne1 -p 40001 -b 3 -z 4 --silent-mode=true -i -M mirrorless -C 1 gpadmin 12065 0.0 0.0 186248 1436 ? Ss Feb20 0:00 postgres: port 40002, logger process gpadmin 12067 0.0 0.0 186240 1432 ? Ss Feb20 0:00 postgres: port 40000, logger process gpadmin 12069 0.0 0.0 186248 1436 ? Ss Feb20 0:00 postgres: port 40003, logger process gpadmin 12073 0.0 0.0 186248 1440 ? Ss Feb20 0:00 postgres: port 40001, logger process gpadmin 12074 0.0 0.0 188348 1448 ? Ss Feb20 0:00 postgres: port 40002, stats collector process gpadmin 12076 0.0 0.0 450320 23988 ? Ss Feb20 0:02 postgres: port 40002, writer process gpadmin 12077 0.0 0.0 450116 2448 ? Ss Feb20 0:00 postgres: port 40002, checkpoint process gpadmin 12078 0.0 0.0 450172 1496 ? S Feb20 0:00 postgres: port 40002, sweeper process gpadmin 12080 0.0 0.0 188340 1444 ? Ss Feb20 0:00 postgres: port 40000, stats collector process gpadmin 12081 0.0 0.0 450120 22636 ? Ss Feb20 0:02 postgres: port 40000, writer process gpadmin 12082 0.0 0.0 450108 2520 ? Ss Feb20 0:00 postgres: port 40000, checkpoint process gpadmin 12083 0.0 0.0 450164 1492 ? S Feb20 0:00 postgres: port 40000, sweeper process gpadmin 12084 0.0 0.0 188348 1444 ? Ss Feb20 0:00 postgres: port 40003, stats collector process gpadmin 12085 0.0 0.0 450292 24060 ? Ss Feb20 0:02 postgres: port 40003, writer process gpadmin 12086 0.0 0.0 450116 2448 ? Ss Feb20 0:00 postgres: port 40003, checkpoint process gpadmin 12087 0.0 0.0 450172 1492 ? S Feb20 0:00 postgres: port 40003, sweeper process gpadmin 12089 0.0 0.0 188348 1452 ? Ss Feb20 0:00 postgres: port 40001, stats collector process gpadmin 12090 0.0 0.0 450292 22376 ? Ss Feb20 0:01 postgres: port 40001, writer process gpadmin 12091 0.0 0.0 450116 2456 ? Ss Feb20 0:00 postgres: port 40001, checkpoint process gpadmin 12092 0.0 0.0 450172 1500 ? S Feb20 0:00 postgres: port 40001, sweeper process gpadmin 12110 0.0 0.6 407588 197676 ? Ss Feb20 0:00 /opt/gp/bin/postgres -D /opt/master/gpsne-1 -p 5432 -b 1 -z 4 --silent-mode=true -i -M master -C -1 -x 0 -E gpadmin 12111 0.0 0.0 186244 1504 ? Ss Feb20 0:00 postgres: port 5432, master logger process gpadmin 12114 0.0 0.0 188344 1448 ? Ss Feb20 0:00 postgres: port 5432, stats collector process gpadmin 12115 0.0 0.0 407748 3796 ? Ss Feb20 0:01 postgres: port 5432, writer process gpadmin 12116 0.0 0.0 407720 2380 ? Ss Feb20 0:00 postgres: port 5432, checkpoint process gpadmin 12117 0.0 0.0 408692 4112 ? S Feb20 0:00 postgres: port 5432, seqserver process gpadmin 12118 0.0 0.0 675276 5536 ? S Feb20 0:09 postgres: port 5432, ftsprobe process gpadmin 12119 0.0 0.0 407588 1436 ? S Feb20 0:00 postgres: port 5432, sweeper process gpadmin 14626 0.0 0.0 542312 12580 ? Ssl Feb20 0:00 postgres: port 5432, gpadmin anomaly [local] con13 [local] cmd22 idle gpadmin 20502 0.0 0.0 541280 10736 ? Ssl 16:31 0:00 postgres: port 5432, gpadmin sw 192.168.1.2(51531) con17 192.168.1.2(51531) cmd8 idle
まとめ
このように、Greenplumは実はちょっとした用途に使う形で、単に「マルチコアを活かせる使いやすい超高速なPostgreSQL」として使うことができます。SQL処理をスケールアウトできるMPPDBが遂にOSS化されたことは個人的に非常にうれしく、本当にいい時代になったなと感じます。
データを対話的に解析する際、1つのクエリに対して30秒待たされるのと、3秒しか待たされないのとでは効率に天と地の差があります。快適なSQLデータ解析ライフを過ごしたい人に、是非おすすめします。