技術者ブログ
クラウド型WAF「Scutum(スキュータム)」の開発者/エンジニアによるブログです。
金床“Kanatoko”をはじめとする株式会社ビットフォレストの技術チームが、“WAFを支える技術”をテーマに幅広く、不定期に更新中!
テキストデータ処理を簡単にマルチコア対応にするJavaフレームワーク、MCPの実装
はじめに
ログファイルなどの行指向のテキストデータを加工するタスクでは、多くの場合、awkやsed、あるいはperlなどのプロセスをパイプで組み合わせる、いわゆるワンライナー的なアプローチがよく使われます。また、ワンライナーでは収まりきらないようなちょっと込み入った処理を行いたい場合などは、各自得意なプログラミング言語でコードを書くことになります。このとき、多くの場合は、標準入力から1行ずつデータを読み込み、順番に処理していくというアプローチになるかと思います。
しかしこのようなアプローチには大きな欠点があります。それはCPUリソースを1コア分しか消費できないということです。grepのような簡単な処理で、CPUリソースではなくI/Oがボトルネックになる場合はそれでもまったく問題ありませんが、CPUがボトルネックになるような場合には、1つのコアだけでなく、マルチコアを使うことによって、処理が数倍速くなる可能性があります。現在ではサーバ・クライアントを問わずほとんどのマシンが4コアあるいはそれ以上のコアを搭載していますので、シングルコアのパワーしか活かせない加工処理は多くの場合ナンセンスであると言えるでしょう。
今回のエントリでは、筆者が開発した、Javaを用いて手軽にマルチコアを生かしたデータ処理を可能にするためのフレームワーク、MCP(MultiCore Parser)を紹介します。MCPはマルチスレッドを用いて複数のコアを生かした並列処理を可能にするものですが、ユーザがデータを加工するために書くコードからは、その詳細は隠蔽されています。そのため、ユーザはスレッドやロックについてはまったく意識することなく、従来のように各行に対して行う処理を簡潔に記述するだけで、自動的にスケールする処理が実現できるようになっています。MCPはオープンソースです。
ダウンロード
コンパイルと実行時に必要となるjarファイルはhttp://www.jumperz.net/tools/mcp.jarからダウンロードできます。ソースコードについてはGitHubから入手可能となっています(ライセンスはGPLです)。
使い方
ユーザはnet.jumperz.io.multicore.MParserインターフェースを継承したクラスを実装します。そして自分が行いたい処理を、parseという名前の関数として実装します。この関数では引数としてString型のインスタンスが1つ渡されますが、これが加工対象の各行のデータとなります。parse関数はアプリケーションが処理するテキストデータ全体の行数と同じ回数だけ呼び出されます。
parse関数の戻り値もString型で、これは加工後のデータを示します。戻り値にnullを返すこともできます。例えばgrepのような処理を行う場合は、ある行に対する加工後の結果が存在しないケースがあります。そのような場合にはnulを返すようにしてください。
それでは、非常にシンプルな例として、「入力された行の文字を、すべて大文字に変換する」という処理を実装してみます。この場合、以下のようなクラスを定義します。
public class UpperCase
implements net.jumperz.io.multicore.MParser
{
//--------------------------------------------------------------------------------
public String parse( String s )
{
return s.toUpperCase();
}
//--------------------------------------------------------------------------------
}
StringクラスのtoUpperCaseを呼び出すだけの簡単な実装となっています。
実行するには、mcp.jarと上記クラスがともにクラスパスに含まれた状態で、javaコマンドからnet.jumperz.app.MCP.MCPクラスを呼び出します。また、引数として、上記のようにparse関数を実装したクラス名を与えます。UpperCaseクラスはmcp.jarに含まれているため、例えばoutputというディレクトリ内にmcp.jarが置かれている場合には、以下のようにコマンドラインから実行することで各行を大文字にする処理が実行されます(Linux環境でbashを用いた例となります)。
echo -e 'foo\nbar\nbaz' | java -cp output/mcp.jar net.jumperz.app.MCP.MCP UpperCase
実行結果は以下のようになります。
FOO BAR BAZ
上記の例はわずか3行の入力に対する処理であるためマルチコアを生かした処理とはなりませんが、入力されるデータが数十万行あるいはそれ以上あるような場合には、それぞれのコアを有効に使った処理が行われます。
並列度のコントロール
デフォルトでは並列度(スレッド数)は4になっています。しかし処理するマシンがもっと多くのコアを搭載している場合には、並列度をさらに上げることでより高速に処理が行われる可能性が高くなります。そのような場合、以下の例のように引数として『--thread-count 12』などを与えることにより、並列度を指定できます。
java -cp output/mcp.jar net.jumperz.app.MCP.MCP --thread-count 12 UpperCase
バッチ処理対象となる行数のコントロール
標準入力から読み込まれるテキストデータは、デフォルトでは10000行ずつのブロックに分けられ、各スレッドはそれぞれ1ブロックずつ処理していきます。以下の例のように引数として『--batch-size 100』などを与えることにより、1ブロックに含まれる行数を変更できます。
java -cp output/mcp.jar net.jumperz.app.MCP.MCP --batch-size 100 UpperCase
実際にどの程度高速化されるのか?
MCPを使用することで処理が実際にどの程度高速化されるのかを、Linuxのegrepコマンドとの比較で見てみます。例として、850万行ほどのApacheのログファイル(サイズは約1GB)について、WordPressのPHPファイルへのアクセスを示す行を抽出してみます。正規表現としては『/wp-.*\.php』を使用します。次のようにegrepコマンドを使ってみたところ、処理はちょうど60秒かかりました。
cat access_log | egrep '/wp-.*\.php' > /dev/shm/egrep_result
次に、MCPを使ってみます。正規表現を使ったgrepを実現するために、次のようなnet.jumperz.io.multicore.example.MEGrepクラスが実装されています。
package net.jumperz.io.multicore.example;
import java.util.regex.Pattern;
import net.jumperz.io.multicore.MParser;
public class MEGrep
implements MParser
{
private Pattern pattern;
//---------------------------------------------------------
public MEGrep()
{
pattern = Pattern.compile( System.getProperty( "egrep" ) );
}
//---------------------------------------------------------
public String parse( String s )
{
if( pattern.matcher( s ).find() )
{
return s;
}
else
{
return null;
}
}
//---------------------------------------------------------
}
上記のようにパターンはシステム変数としてコマンドラインの-Dオプションで与える仕様となっているため、コマンドラインに以下のように入力して実行します。
cat access_log | java -Degrep='/wp-.*\.php' net.jumperz.app.MCP.MCP net.jumperz.io.multicore.example.MEGrep > /dev/shm/mcp_result
処理にかかった時間はわずか6秒(約140万行/秒)で、egrepより10倍速いという結果になりました。
この速度の差は『Javaの正規表現マッチングとegrepとの性能差』と『シングルコアかマルチコアか』という2点から来るものです。MCPでわざと『--thread-count 1』としてシングルコアのみを使ってみたところ、17秒という結果でした。このことから、元々Javaの正規表現マッチングがegrepよりも3倍強速く、それをマルチコアで処理することでさらに数倍処理が速くなっていることがわかります。テストを実施したマシンはクアッドコアであるため、コア数がもっと多いマシンであれば、さらに速く処理することが可能でしょう。
ところで、単純なgrepとの比較の場合には、CPUよりもI/Oがボトルネックになることから、MCPで実装したものよりもgrepコマンドの方が速いという結果になりました。
MCPの実装の解説
以下はMCPの中身に関する記述となりますので、興味がある方のみお読みいただければ幸いです。
MCPの具体的な実装はnet.jumperz.io.multicoreパッケージに含まれており、下図のような関係になっています。
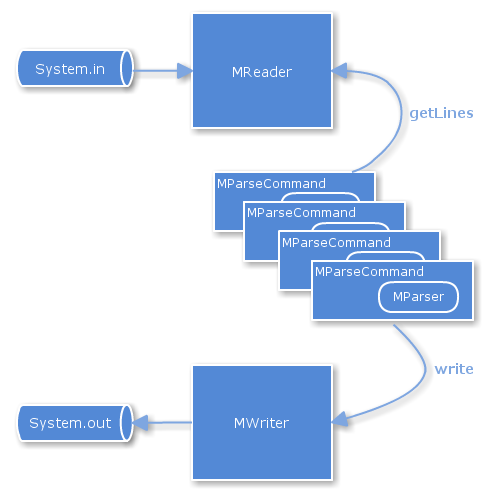
MReaderクラスがSystem.inへのアクセスを、MWriterクラスがSystem.outへのアクセスを制御しています。それぞれアプリケーション起動中に1つだけインスタンスが生成されます。並列化される処理については、MParseCommandクラスのインスタンスが複数(並列度と同じ数)生成され、それぞれ別のスレッドで動作することで行われます。ユーザが実装するMParserインターフェースを継承したクラス(図中では単にMParserと記述)は複数のインスタンスが生成され、それぞれ1つずつMParseCommandのインスタンス内に所持されます。
各MParseCommandはMReaderのgetLinesを呼び出し、標準入力から読み込まれたデータを、ある程度まとまった数ずつ取得します(先述したブロックがこれに当たります)。このとき、自身が受け取ったブロックが何番目だったのかというインデックスについても同時に受け取ります。このインデックスは、処理後にデータをMWriter経由でSystem.outに出力する際に、データの並び順を揃えるために使われます。ブロックをJSONで表現すると次のようになります。例えばテキストデータの内容が、1行目が『line1』、2行目が『line2』...となっており、ブロックの単位が3行(先述したようにデフォルトでは10000行です)だとします。
{
"index" : 0,
"data" : [
"line1",
"line2",
"line3"
]
}
同様に、2つめのブロックは次のようになります。
{
"index" : 1,
"data" : [
"line4",
"line5",
"line6"
]
}
System.inからの読み込みは、並列度を上げてもパフォーマンスアップには繋がりません。また、並列でアクセスしてしまうとデータの整合性が乱れてしまいます。そのため、MReaderクラスのgetLinesはsynchronizedで実装されており、複数のMParseCommandのうち1つだけが実行することができます。MParseCommandはgetLinesを終えて上記JSONで表現されるようなブロックを受け取ると、自身のスレッド上でパース処理を行います。このとき、別のMParseCommandがMReaderのgetLinesを呼び出すことが可能となり、パース処理と、読み込み処理が並列に走ることになります。
処理を終えたMParseCommandはMWriterのwriteメソッドを使って上記JSONに似たブロックを渡します。このときdataに処理済みの行が格納されているため、たとえば先に示した例であるUpperCaseであれば、次のようなブロックとなります。
{
"index" : 0,
"data" : [
"LINE1",
"LINE2",
"LINE3"
]
}
MWriterクラスのwriteメソッドもMReaderと同様の理由によりsynchronizedで実装されており、たった1つのスレッドだけが実行可能です。MParseCommandの各スレッドは勝手に処理を行うため、場合によっては後からブロックを受け取ったスレッドが先に処理を終え、MWriterクラスのwriteメソッドを呼び出す可能性があります。仮にこのスレッドがデータをSystem.outから出力してしまうと、処理結果が本来あるべきものと順番が異なってしまい、バグとなってしまいます。
MWriter内には変数として「次に出力すべきブロックのインデックス」が保持されているため、このような場合、writeメソッド内でwaitを呼び出すことでいったんスレッドを停止します。そして本来、次に出力するべきブロックを保持しているスレッドがwriteメソッドを呼び出すと、System.outにデータを出力し、その後notifyAll()が実行され、先に来てしまっていたスレッドが起こされます。起こされたスレッドは再度インデックスの比較を行い、自分が出力する番であればSystem.outからデータを出力します。そうでない場合(2つ以上の順番を飛び越してしまっていた場合)はまたwaitを呼び出し、スレッドは停止します。このような処理を簡単にwaitとnotifyで実装できるのが、Javaのいいところです。
ここで、『先に処理を終えてしまったスレッドは、ブロックだけをMWriterに渡して、次の処理に移ればよいのでは?』と考えるかと思いますが、そのようにしてしまうと、System.outからの出力が遅い場合に、大量のデータがMWriter内に保持され、結果としてメモリを大量に消費することになってしまいます。いろいろなパターンでテストしてみた感じでは、MReaderおよびMWriterがsynchronizedであることについては(そもそも入力と出力はある程度のボトルネックとなるため)パフォーマンスへの悪影響はないようです。
おわりに
今回はJavaで記述した単純なテキストデータ処理を、簡単にマルチコア対応にするフレームワーク、MCPを紹介しました。より大量のデータの加工や分析であればHadoopのような選択肢もあるかと思います。MCPはワンライナーとHadoopの間に位置する、手軽にマルチコアを活かす技術として使えるものだと考えています。フィードバックなどございましたら@kinyukaまで。