技術者ブログ
クラウド型WAF「Scutum(スキュータム)」の開発者/エンジニアによるブログです。
金床“Kanatoko”をはじめとする株式会社ビットフォレストの技術チームが、“WAFを支える技術”をテーマに幅広く、不定期に更新中!
Tomcat/Javaで対話的にデータサイエンスする
はじめに
Scutumではベイジアンネットワークをはじめ、データサイエンスを積極的に導入して高性能のWAFを実現することを目指しています。データサイエンスやデータマイニングでは、解析対象のデータに対して対話的に解析を行うことが多くなります。今回は基本的には「対話的プログラミング環境でない」Javaで、データを対話的に解析する方法をご紹介します。
一般的なJavaアプリケーションのライフサイクル
JavaはRに代表されるような対話的なプログラミング環境とは異なり、基本的には一度コードを書いたらそれがコンパイルされ、ある程度「固定」されたものになり、プロセス起動中は「事前に準備したコード」を使って処理をします。
Javaでデータを解析する場合には、プロセスの起動後にデータが読み込まれ、解析処理が行われ、何かしらの結果をはき出して終了する、というのが1つのステップになります。
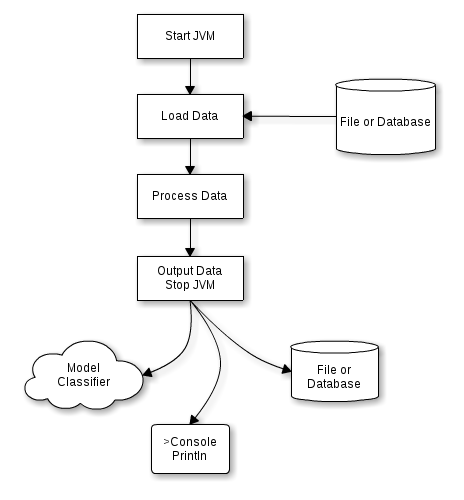
解析を実際に行う人(以下、解析者とします)はこのJavaプロセスの実行結果として得られた分類器のモデル(多くの場合バイナリ)や統計情報(テキスト型の情報)、あるいは何かしらの加工後のデータ(CSVファイルやデータベースに格納されたもの)を得ると、次に何をすべきか?と考えます。そしてその考えを実行するためにJavaコードを作成あるいは変更し、次のステップとして実行します。これを、何度も繰り返していきます。
この各ステップにおいて、JVMは起動と停止を繰り返すため、基本的にJVMの「状態」はステップ間において保持されません。そのため、メモリ上に大量のデータをロードしたり、加工処理したものがあったとしても、それらを次のステップに引き継ぐためには一度ファイルやデータベースに格納する必要があり、非効率的だと言えるでしょう。Rのような対話的な環境であれば、このような問題はありません。
データサイズが小さい場合には「データのロード」が短時間で行われるのでこの問題はあまり顕在化しませんが、データサイズが数GBから数十GBくらいになると、JVM起動後のデータのロードに数十秒以上かかるようなケースがあり、対話的な解析がスムーズに行えない状態となってしまいます。
「データを処理する」「結果を見る」「やり方を変えて、また処理する」「結果を見る」という繰り返しの中では「コードを変更する」というのが必須の要素となりますが、Javaでは基本的にはこれができません。そのため、「対話的に処理できる」ことが重要となるデータ解析作業には、Javaは向いていないと考えることもできます。
なぜJavaでデータ解析を行うのか?
前項のように「対話的に作業しづらい」ことからJavaはデータ解析に向いていないと考えることもできますが、ここで一度振り返って、そもそも「なぜデータ解析にJavaを使う(使いたい)のか?」を簡単に整理します。比較対象はコマンドライン、RDBMS(SQL)、Rなどです。
パフォーマンスが優れている
Javaでデータ解析するメリットとして最初に挙げるべきはそのパフォーマンスです。文字列関係の処理や正規表現のエンジンが非常に速く、例えば正規表現の検索であれば、Linuxの一般的なコマンドであるegrepを使うよりも、5倍以上速く処理できることがあります。また集計処理などにおいても、近年非常に高速であると評価の高いPostgreSQLよりも20〜30%程度は速いことが多いです。
(筆者はまだ試せていませんが)Java8のストリーミングAPIではマルチコアを活かしたコレクションに対する処理も手軽に書けるようになったようなので、「大量の行から該当する行を絞り込む」だけのような単純な処理でも、Javaでやるというのは悪くない選択肢です。
複雑な処理ができる
もちろんJavaでの解析においては単純な処理に限らず、プログラミング言語の機構がそのまま全てデータ解析のために使えるので、高速なだけでなく、必要な場合には複雑な処理が可能です。コマンドラインでgrepやsort、awkなどを使うよりも統合的に複雑な処理を組み立てやすい面があると思います。SQLやRに対しても、この点でやや勝っているのではないでしょうか。
各種のライブラリが揃っている
各種のRDBMSに接続するためのJDBCドライバをはじめ、データ解析という場面で活躍するJava用のライブラリは非常に豊富です。Hadoopエコシステムなどもこれに含まれますし、機械学習用のWEKAなどもあります。ただし、やはり統計的な処理についてはRには負けているように思います。
IDEの強力な支援機構が使える
データ解析の最中には、時にステップ実行によるデバッグが非常に便利に感じます。IDEの強力な支援機構を使ってステップ実行することで、データ解析のある時点を細かくドリルダウンすることができます。また、コードを書く際の補完機能なども便利です。
メモリを有効に使える
JVMでは多くの場合、文字列のデータはメモリ上で重複しないように管理されるため、例えばウェブのアクセスログなどのようにパース後に同じ内容の文字列が大量に存在するようなデータを解析する場合や、MongoDBなどからJSON形式のデータを大量にロードして扱う場合(キーの文字列が大量に重複する場合)でも、メモリを有効に利用することができます。結果として、このような機構を持たない環境よりも多くのデータをインメモリで解析することができます。
Javaで対話的なデータ解析を可能にする方法
このようにJavaでデータ解析を行うメリットはいくつか存在するので、解析者がJavaが得意である場合には有力な選択肢となります。先に触れたように「対話的に処理しづらい」という最大の問題があるのですが、この点についての解決法もいくつか存在します。
JRuby等のJVM上の言語を使う方法
JVM上で動作するJRubyやClojureなどの対話的な開発が可能な言語を使う方法が考えられます。これは悪くない選択肢ですが、生のJavaと比べるとパフォーマンスが時に大きく劣ったり、デバッグがしづらかったりするというデメリットが存在します。
アプリケーションサーバを使う方法
ここでやっと本題に辿り着きました。筆者が好きなこの方法は、Tomcat等のアプリケーションサーバを使うものです。アプリケーションサーバにはJSPのコードをランタイムにコンパイルする機構が備わっているため、JVMを起動したままJavaのコードを次々に変えていくことができます。この機構は非常に安定して動作するため、安心して使うことができます。
JSP内に解析のためのJavaのコードを記述し、コマンドラインからcurlなどの方法で、手軽にHTTPリクエストを送信してそのJSPを呼び出します。JSP内に記述されたJavaのコードはメモリ上のデータにアクセスし、何か処理を行い、その結果をJavaの通常のオブジェクトとしてメモリ上に保持したり、あるいは単純な値であればコンソールやJSPの出力として解析者に表示したりします。
Tomcatはローカルのマシンで、Eclipse IDE for Java EE等を使って動作させます。JSP内のJavaコードを、エディタの補完機能を使いながら変更していくことができます。
解析者は上記の結果を確認し、思考したら、続いて必要に応じてJSP内のJavaコードを変更します。そして次のHTTPリクエストを送信してその処理を実行します。このサイクルが続く間、JVMは起動したままになるため、メモリ上のデータは消えず、対話的なデータ解析処理が可能になります。下図中、赤い線がデータ解析作業の基本的なサイクルとなります。必要に応じて何度でもコードやデータを変更し、ステップを繰り返しながら、目的を探ったり、目的に近づいたりしていきます。
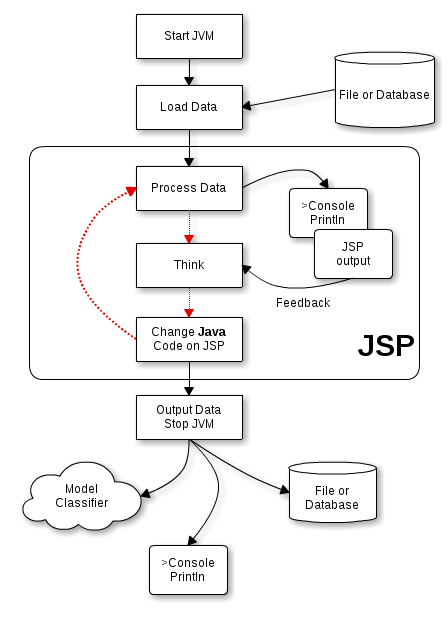
例えば数十GBくらいのデータを一番はじめにメモリ上のListやMapにロードしてしまい、その後はずっとメモリ上に保持しながら、それに対していろいろな(Javaで記述した)クエリを投げ、都度結果を取得することができるようになります。このときロード対象のデータはJSP以外のクラスのstaticメンバなどとして保持しておくと、アクセスしやすいと思います。数十GBのデータは常にメモリ上にあるため、本当に高速に処理が可能になります。ただし永続化はされないので、処理をすべて終えたり、その日の仕事として終わりにする場合には別途保存するか、ファイルやデータベースからのロード方法を改めて確認しておくなどの必要がある点はデメリットです(例えばRDBMSであれば、データを格納した時点で永続化が完了し、そのまま解析できる安心感があります)。
大きなデータセットをWEKAのライブラリを使って機械学習する場合、ExplorerなどのGUIのツールだとGUIの描画が原因でフリーズしてしまうようなケースがあり、このような場合はJavaのコードだけで扱う必要が出てきます。このときこのアプリケーションサーバを用いる方法だと、メモリ上に大きなInstancesや大量のInstanceを保持したまま、パラメータを変えていろいろなアルゴリズムを試してみる解析手法が可能になります。
このように、本来ウェブアプリケーションを動作させるために用いるアプリケーションサーバを、解析者が自分の手元のデータ解析のプラットフォームとして使うというのは、非常に実用性が高い、便利な方法だと思います。
まとめ
今回は「実行中にコードを変更しづらい」というJavaのデメリットをJSPを使うことで克服し、高速かつ快適に対話的なデータ解析を行う方法を紹介しました。1台のメモリに収まりきるサイズのデータ解析であればHadoopエコシステムに手を出すこともなく、高レスポンスな環境で作業することができます。
この記事に関するフィードバック等は、お気軽に@kinyukaまでお寄せください。