技術者ブログ
クラウド型WAF「Scutum(スキュータム)」の開発者/エンジニアによるブログです。
金床“Kanatoko”をはじめとする株式会社ビットフォレストの技術チームが、“WAFを支える技術”をテーマに幅広く、不定期に更新中!
Log4jで話題になったWAFの回避/難読化とは何か
はじめに
2021年12月に発見されたLog4jのCVE-2021-44228は、稀に見るレベル、まさに超弩級の脆弱性となっています。今回、私はTwitterを主な足がかりとして情報収集を行いましたが、(英語・日本語どちらにおいても)かなりWAFそのものが話題になっていることに驚きました。ある人は「WAFが早速対応してくれたから安心だ!」と叫び、別の人は「WAFを回避できる難読化の方法が見つかった。WAFは役に立たない!」と主張する。さらにはGitHubに「WAFを回避できるペイロード(攻撃文字列)一覧」がアップロードされ、それについて「Scutumではこのパターンも止まりますか?」と問い合わせが来るなど、かなりWAFでの防御とその回避方法について注目が集まりました。
実はWAFにおいては、「回避(EvasionあるいはBypass)」との戦いは永遠のテーマです。これは今回Log4jの件で強く意識されたように「WAFが役に立つか、あるいは無駄なセキュリティ投資になるか」の境目を決定する要素であり、そのため非常に、本当に非常に重要な要素です。実は我々Scutumの開発チームはこの部分に特に力を入れているため、「WAFの回避テクニック」に世間の注目が集まるのは少しうれしい部分もあったりします。
今回はこの「WAFの回避」に焦点を当て、Log4jでの具体的な例を中心に、難読化やそれを見破るいたちごっこについて書いてみます。
WAF回避のための2つのアプローチ
WAFを回避してウェブサーバに攻撃を届けるために、主に2つのアプローチが存在します。
- 1. WAFをまるごと回避する
- 2. 個別の検知ロジック(シグネチャなど)を回避する
今回のLog4jで注目を集めたのは後者です。つまり「Log4jの攻撃を見つけようとするロジックを、どうやって捕捉されずに通り抜けるか」ということです。
しかし、実はより重要なのは前者です。「WAFをまるごと回避する」というのは「WAFがそもそも認識しない方法で攻撃を届ける」ことです。この方法が見つかってしまった場合、攻撃者はそれぞれの検知ロジック(シグネチャなど)を通らずにウェブサーバにペイロードを送り届けることができてしまいます。この場合、難読化は必要ありません。そして最悪のケースでは、SQLインジェクションやコマンドインジェクション、そして今回のLog4jなどを含む、全ての分野の攻撃がそこから可能になります。
これ(WAFまるごとの回避)はWAF開発者としてはまさに悪夢のようなシナリオであるため、Scutumチームでは全力でまずここの対策をしています。
1. WAFまるごと回避の詳細
WAFがまるごと回避されてしまうパターンとして、次のようなものがあります。
- 1-1. そもそもWAFが見ていない箇所を探す
- 1-2. WAFがデコードしない箇所にエンコードしたペイロードを入れる
1-1. そもそもWAFが見ていない箇所を探す
まず前者から解説します。例えばPOSTリクエストの場合、HTTPリクエストは、次の図のような構成になっています。
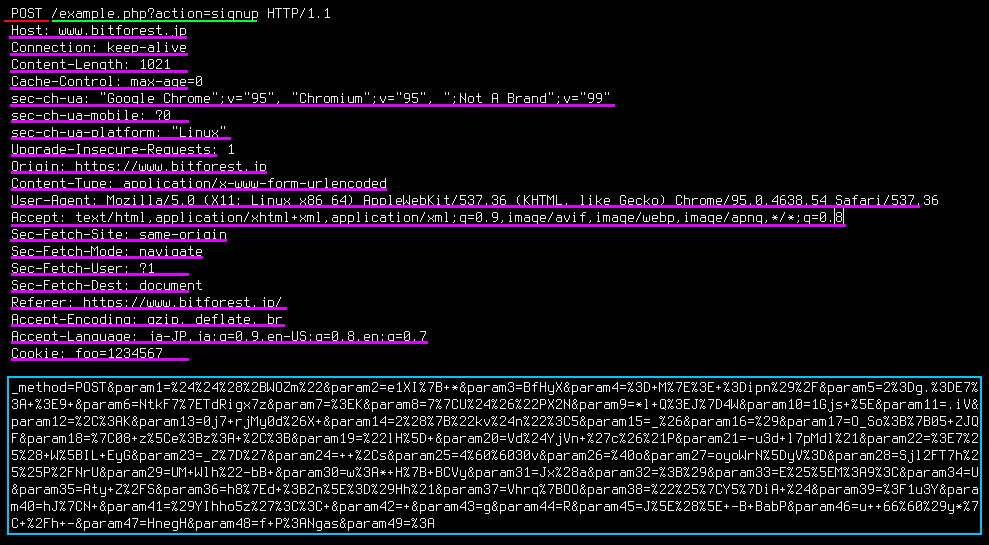
ペイロードは主にURL(黄緑)、HTTPヘッダ(紫)、そしてボディ(水色)に含まれます。
例えば今回のLog4jの脆弱性について考えると、アプリケーションが何かしらLog4jを使ってログに記録していれば脆弱となることから、これら3箇所についてすべてが攻撃対象になりえます。例えばURLそのものをログに記録したり、クエリ文字列をログに記録することは当たり前に起こるシチュエーションです。また、User-Agentや、クライアントからHTTPヘッダ経由(例えばX-CSRF-Tokenなど)で送られてくる情報がログに記録されることも良くあるでしょう。そしてボディ部に含まれるパラメータもクエリ文字列と同様、アプリケーション内で処理に使用されたり、その際にログに記録されることが十分に考えられます。つまりWAFとしてはこの3箇所すべてをきちんと検査対象として扱うことが求められます。
「え、そんなの当たり前では」と思われた読者の方もいると思いますが、いくつかの(他社さんの)WAFでは、これらのうち、部分を限定して検査しているものが存在します。とある大手クラウドサービスにオプションとして用意されているWAFでは、上記の図の紫部分について全体をカバーはせず、User-AgentやReferer、Cookie等の一部のヘッダ項目についてのみ、Log4jの検査対象としているようです(12/13時点で私が実際にテストして確認)。他のヘッダ項目は無防備な状況であり、これは好ましいとは言えません。私以外にもこの点に気づいた人はいたようで、英語圏のTwitterにおいて、数人が「この○×のWAFはUser-Agentくらいしか見ていないようだ」「これではLog4jへの攻撃を防ぐには不十分だ」等とつぶやいていました。
12月14日にScutumで観測した攻撃の中には、x-api-versionヘッダにのみペイロードを含むものがありました。ペイロードは難読化されていませんでしたが、これはUser-AgentやCookie等だけを検知対象にしているWAFや、ヘッダをそもそも見ない状態で運用しているWAFでは止まりません。
Scutumは全ヘッダ項目を検査対象としています。WAFとしては当然そのように動作するべきだと思いますし、おそらく多くのWAFはそうだろうと思います。
この例のように、HTTPリクエスト中に「そもそもWAFが見ていない」箇所があると、WAFの回避は簡単に成立してしまいます。この場合、難読化の技術は不要です。また以前の記事に書いたように、特に大手クラウドのオプション型WAFは誰にでも自由に調査されてしまうため、今後ますます攻撃者が意識して回避してくる確率が高くなるだろうと予想します。
WAFの防御能力について検証する際には、上記のようなHTTPリクエスト中の基本的な箇所をすべて検知対象としているかどうか、をまず最初に調べることをおすすめします。難読化とそれによる回避について心配するのは、その次のステップになります。
1-2. WAFがデコードしない箇所にエンコードしたペイロードを入れる
次に後者です。例えばXMLでは、次のようなエスケープ(エンコード)が可能です。
同様に、JSONについても
WAFが正しくデコードできない場合、その部分では全ての分野の攻撃が通り抜けてしまいます。そのため、WAFの防御能力について検証する際には、保護しようとしているウェブアプリで使っている形式(XMLやJSONなど)について、WAFが正しくデコードし、ウェブアプリ側と同じ文字列として認識できているかを確認することをおすすめします。
仮にこの点を攻撃者が狙う場合、ある意味でそのWAFが「読めない」形であるため、これもある種の「難読化によるWAFの回避」と言えるかもしれません。しかし一般的には「難読化」はもう少し技術的に難しいものを指すケースが多く、この1-2のケースは単なる「仕様の(インピーダンス)ミスマッチ」と呼ぶほうが適切かと思います。
1-1と同じく1-2もWAFとして致命的に重要な点であるため、Scutumではとても気を使って実装しています。
2. 個別の検知ロジックの回避
続いて、まさに今回話題になった「難読化によるWAF回避」の舞台となる、個別の検知ロジックの回避です。
上述した「1. WAFをまるごと回避する」が不可能である場合、攻撃者は個別の攻撃に対する検知ロジックをかいくぐろうとしてきます。
Log4jのケース
今回のLog4jの攻撃では、JNDIの機能を悪用し、LDAP経由でコードインジェクションをする、という方法がもっとも広く使われています。脆弱性の震源地であるLog4j内の「Lookup」と呼ばれる機能では、${という区切り文字列に続いてjndi等のキーが続くことでLookupが動作します。そのため攻撃のペイロードのもっとも原始的なものは次のような形でした。
${jndi:ldap ...(後略
多くのWAFでは、まず最初に「${jndi」などの部分を単純な文字列マッチング(シグネチャ)で見つけるアプローチが採られたのではないかと推測します。Scutumでも最初はそうしました。しかし、Log4jのソースコードを読んでみたところ、変数をパースするコードに再帰している箇所があることが判明し、例えば次のような文字列が上記と同じくJNDIのLookupを行ってしまうことがわかりました。
${j${:dummy:-n}di: ...(後略
この場合は、先の単純なシグネチャでは見つからなくなります。ペイロードが「jndi」という文字列そのものを含まないにも関わらず、Log4j内部では「jndi」という文字列として扱われてしまう状況です。これがまさに「難読化によるWAFの回避」の典型的なパターン、いたちごっこの始まりです。検知したいWAF側は、より複雑なロジックを構築する必要が出てきます。
防御するWAF側がいたちごっこに勝利することを極端な方向で考えれば、例えば「${があったら問答無用でブロックする」というシンプルなロジックを構築することもできます。Log4jでは${はそれ以上難読化することができないので、これで全ての攻撃を防ぐことができます。しかしその場合、問題になるのは誤検知(False Positive)です。ウェブアプリケーションが正常な通信で${という2文字の並びを使うことができなくなるため、場合によってはウェブアプリケーションがその役目を果たせず、ビジネスの邪魔をしてしまうかもしれません。
複数のお客様の環境に基本的に同一の検知ロジックを提供しているWAFでは、当然上記のような確信を持つことはできません。むしろ、数多くある様々なお客様の通信には、正常な利用の範囲において${という2文字の並びが登場することがある、と考えるのが自然です。そのため、上記の単純な割り切りは実際には行うことができません。
このようにWAF側は「攻撃はできるだけ止めたい」「正常な通信はなるべく止めたくない」という狭間で、難読化された文字列の検出ロジックを構築する必要があるのです。
今回の場合、様々な難読化されたペイロードがTwitterやGitHubなどでまたたく間に広がりました。仮にシグネチャ、正規表現でこれらに対応しようとすると、それらを情報として集め、全てにマッチし、一方で正常通信にはマッチ(誤検知)しなさそうな複雑怪奇な正規表現を書く必要が出てきてしまいます。また、後からさらに別の難読化されたペイロードが出てきたらまたやり直す必要があり、進めるにつれてメンテンナンスが難しくなる困難な道です。Twitter上で次のように正規表現で頑張っている人を見ました。
I know that using regex is dumb and shit, but it's just first-line defense. This one I made is capable to detect obfuscated payloads and should produce very few false positives:
— egglessness (@egglessness_) December 11, 2021
\${(\${(.*?:|.*?:.*?:-)('|"|`)*(?1)}*|[jndi:(ldap|rm)]('|"|`)*}*){9,10}#log4j #Log4Shell pic.twitter.com/Q2LNmZpexY
Scutumではこのような「シグネチャだと辛そうな」場合、難読化を可能にする対象のソフトウェア(今回ではLog4j)の実装とScutumの間のインピーダンスミスマッチをできるだけ減らすことを検討します(できない場合は、ベイジアンネットワークを使います)。
今回、Twitterで難読化が話題になるよりも先に、Scutum開発チームのメンバーが変数の再帰的な確定によるWAFの回避が可能であると気づきました。そこでシグネチャでの最初の対策を投入後、すぐにパーサの開発に取り掛かりました。Log4jと同じアルゴリズムで文字列を解析し、Log4jがLookupする際にキーにする文字列をまったく同じようにScutumのコード内で取得できるようにします。このようにすれば、いくら難読化されていても、Log4jと同じように例えば「jndi」という文字列として認識することができます。非常に効率的な対策であり、誤検知の心配もほとんど無いと言えるでしょう。
完全に余談で恐縮ですが、今回この部分の調査・開発に携わったビットフォレストのエンジニアは全員F1ファンで、この週末は最終戦までもつれ込んだドライバーズ・ワールドチャンピオンシップの決定戦であったため、「何としても早く仕事を仕上げ、F1観戦に影響を出さない」という強い意志にドライブされ猛烈なスピードで調査と開発が進みました(余談おわり)。
「WAFを回避するための難読化」のレベルで言えば、Log4jのケースはそれほど複雑なものではありません。基本的にはかならず対象の文字が出現しますし、例えばreplaceやsubstringのような関数によって自由に文字列を組み立てたりすることもできません。OGNLインジェクションや、次に触れるbashの機能を利用したコマンドインジェクションの難読化に比べれば、比較的WAFで対処しやすいレベルのものだと思います。
コマンドインジェクションのケース
以前こちらの記事に書いたように、Scutumではコマンドインジェクションについても難読化対策を行っています。こちらもLog4jと同じ発想で、専用のパーサを開発することで防御しています。Log4jの難読化と比較するとこのコマンドインジェクション(bash)の難読化は遥かに対応するのが困難であり、Log4jの対応のように1〜2日で出来るようなものではありませんでした。「難読化によるWAFの回避」という意味ではLog4jの例以上に面白い例だと思いますので、プログラマやエンジニアの方はぜひこの記事も読んでみてください。
Gumblar(ガンブラー)のケース
もう10年以上前の話になってしまいましたが、過去にウェブサイトを改ざんしてペイロードを埋め込むGumblarというワームが流行したことがありました。このときはペイロードがJavaScriptの一部として埋め込まれたため、攻撃者はかなり高い自由度でペイロードを文字列変換し、難読化してIPS/IDS等の検知を回避していました。Scutumはこのケースでもインピーダンスミスマッチをゼロにすることを狙い、疑わしい部分を(無害な状態で実施するように工夫した上で)JavaScriptインタープリタに投げ、難読化を見破るというアプローチを取っていました。当時もシグネチャで対応しようとしていた人たちは苦労していたのでないかと思います。
WAFを回避しようとする実例
ここまで「WAFの回避」について説明させて頂きましたが、実際のところ、普段攻撃を観測していて、それほど「WAFを回避しよう」という意思を感じさせるものは多くありませんでした。しかし(徐々にWAFを導入するウェブサイトが増えてきたからか)今回のLog4jのお祭り騒ぎにおいては、難読化された攻撃をそこそこ検出しています。
12/14の時点で、難読化されたLog4jへの攻撃が、全体のLog4j攻撃件数のうち15%ほどを占めています(攻撃対象のウェブサイトと、その攻撃元IPアドレスのユニークな組み合わせをそれぞれ1件としてカウント)。
攻撃者がWAFを意識し、本格的に難読化を導入してくるフェーズに入ったのかもしれません。Scutumではまさにそれに備えているので、今後も状況を注視し、面白い流れがあればブログ等で報告するつもりです。
他社さんのWAFのLog4j攻撃難読化への対応
Log4jの情報収集でTwitterを見ていると「難読化でWAFは簡単に回避されてしまう」というような内容のTweetを英語・日本語問わず沢山見かけました。Scutumは上記のようにパーサで対応したから大丈夫ですが、他社さんのWAFが実際、どのくらい難読化に対応しているのか興味があり、手軽に試すことができる2つについて調査してみました。ここでは具体的な名前は出さないでおきます。
一方のWAFについては、私はいろいろ試してみたものの回避できなかったのですが、研究開発チームの別のエンジニアが(とても短時間で)回避に成功していました。TwitterやGitHubで出回っているパターンについては殆ど止めていたようですが、さらに工夫されると回避出来てしまうようです。
もう一方のWAFについては、(おそらく確実に)回避ができないようになっていました。どうやら
${の右側にjndi:という順番でそれぞれの文字(文字列ではない)が存在していたら止める
というロジックにしたようです。例えば「${ajanadai:」は止まります。そして「${ajanadan:」だと止まりません。これならば確実に(難読化されたとしても)${jdniを止めると思うので、防御としては良いと思います。一方で、誤検知が多少心配になるチューニングになっていると思います。上に書いたような「${があったら全て止める」ほど極端ではなく、それなりに現実的な(防御重視の)妥協点として選択したのだろうと思います。2社さんそれぞれ次のような別のチューニングになっており、同業者として非常に興味深いです。
- 工夫すると難読化による回避を許してしまうが、一方でそれほど誤検知はしないチューニング
- 回避は確実に防ぐが、一方で誤検知が多少起こりそうなチューニング
Scutumのようにパーサを作ってしまえば、難読化に対応できる一方で誤検知はほぼ無くなるため、ここで調査した2社のWAFに比べて良い解決を実装できたと思います。
このようにLog4jの攻撃は(私が見た狭い範囲ではありますが)複数のWAFにおいて難読化されていてもまぁまぁ良く止めているので、「難読化すれば簡単にWAFを回避できる」というのは単純に情報として間違っているな、というのが今の時点での私の結論です(上述のように、そもそもWAFが見ていないヘッダ項目があるような場合はWAFを回避できますが、これは難読化とは関係のない話です)。もちろん、ごく最初のシンプルなシグネチャしか投入されていない時点では、難読化で多くのWAFが回避できただろうと思います。一時的にそういうタイミングがあったとしても、WAF側もいたちごっこに参加していれば、継続的にそうそう簡単に回避されることはないと考えてよいのかなと思います。
まとめ
今回は「WAFの回避」について、Log4jでの例やScutumでのアプローチについて簡単にご紹介させて頂きました。「WAFの回避」という文脈においては、難読化による回避はどちらかというと「細かい事象」であり、一番重要かつ基本になるのはまずリクエスト全体をまんべんなく検知対象とすることです。その先に、細かな難読化との戦いが待っています。まずはWAFをまるごと回避されないようにし、次に個別の攻撃に注目するのがよいでしょう。
難読化によるWAFの回避を防ぐには、まず完全に攻撃者の視点・技術で最初の回避を考える必要があります。そして、次にそれを防ぐ方法を考えます。我々のScutum開発チームは提供しているサービスは防御のものですが、研究開発においては完全に攻撃者視点でWAFを回避する方法を探しており、Scutum自体を回避されないよう常に気をつけています。
Scutumでは
- シグネチャ
- パーサによる解析
- ベイジアンネットワーク
今回のLog4jの脆弱性については、残念ながらゼロデイでの防御はできませんでした。Log4j実装に特有すぎる問題であり、これを予見するのは現実的に難しかったためです。しかしそれにめげず、今後もできればゼロデイで、そうでない場合でもできるだけ早く効果的な解決策を投入できるよう、引き続き精進していきたいと思います。
最後に、今回のLog4j祭りにおいて、Twitter等でさまざまな有益な情報をシェアしてくださった多くの方々に感謝します。