技術者ブログ
クラウド型WAF「Scutum(スキュータム)」の開発者/エンジニアによるブログです。
金床“Kanatoko”をはじめとする株式会社ビットフォレストの技術チームが、“WAFを支える技術”をテーマに幅広く、不定期に更新中!
Isolation Forestの性能を上げるThinning手法
はじめに
Isolation Forestは教師なしでアノマリ検知に使うことのできる優れたアルゴリズムです。性能が高く、またデータの前処理が楽で、とても使いやすいことが知られています。
Scutumではアノマリ検知のアルゴリズムとしてIsolation Forestを使っています(※1)が、最近になり、Isolation Forestの性能を高める「Thinning」という新たな手法を開発しました。これによって、よりWAFとしての攻撃検知精度を高めることができるようになります。今回はこの「Thinning」という手法について解説してみたいと思います。
ソースコード
GitHub上でThinningを利用可能なIsolation Forestの実装を公開しています。
Thinningとは?
林業などにおいて、森全体をより効率的に育てるために、優れた木を残して他を伐採する「間引き」という作業があります。Thinningという名前は、この間引きが由来です。
Isolation Forestではランダムに大量の木を生成しますが、それぞれの木について、例えば「この木は優れている」「この木は役に立たない」というような評価は一切行いません。生成した木は無条件に全てを活かし、使うことを前提にしたアルゴリズムになっています。
しかし実際には木はいずれも完全にランダムに生成されるため、大量の木のうちいくつかは、対象データセットに対するアノマリ検知において、あまり良い結果をもたらさない形になっている可能性があります。これらの、いわば「育ちの悪い木」を特定して捨ててしまおう、という発想がこのThinningです。
Thinningが有効に働く場合の前提
まず前提として、データセットは大量の正常なデータと、少量のアノマリによって構成されているとします。そうでない場合には、この手法は適しません。目安としては、正常なデータの比率が99%以上程度です。これはIsolation Forestを使用するようなケース、アノマリ検知を行いたいケースとしては特に違和感のない状況だと思います。
普通は個別の木には注目しない
ごく普通のIsolation Forestでは一度木を生成したらそれっきりで、それぞれの木そのものに個別に注目することはありません。生成したたくさんの木によって森が構成され、アノマリ検知のフェーズでは、ある1つのデータがどのくらいの深さ(≒異常スコア)となるかを、森全体を使って計算します。この計算はそれぞれの木で計算した値の平均値となります。あくまで平均値しか見ないため、例えばある1つの木が特別にこの平均値から離れた値を出しているような状況であろうとも、特にそのことは発見しませんし、注目もしません。
そもそも木が生成されるプロセスがランダムであるため、仮に他とはずいぶん異なる値を出してしまう木がいくつかあったとしても、そのような「育ちの悪い木」はあくまで森の中の一部でしかありません。最終的に多くの木との平均値をとるので、「育ちの悪い木」の影響は実質的に問題にないレベルとすることができる、と考えるのがIsolation Forestであると言えるでしょう。
どう間引きするか
さてそれではThinningです。生成された木それぞれに注目し、「育ちの悪い木」を見つける方法として、次のようなやり方が考えられます。
ある1つの木で、たくさんのデータ(可能であればデータセット全体)についてそれぞれの深さ(あるいはスコア)を求め、その平均値を取得します。このプロセスは通常のIsolation Forestで行うような「1つのデータを大量の木で評価する」のではなく、「大量のデータを1つの木で評価する」という形になります。この値はいわば「その木のスコアの平均値」です。これを、全ての木について、それぞれで計算します(※2)。すると、この値が高い木もあれば、低い木もある、というように、違いが出てきます。
先述したようにデータセットの大部分は正常なものであるため、この平均値が大きい木(より多くのデータを正常であると判断する木)が、そのデータセットに適した形に作られている木であると考えます。そして逆に、平均値が低いものが「育ちの悪い木」となります。
「木のスコアの平均値」が大きい木を残し、小さい木を捨てる(間引きする)のがThinningです。
アルゴリズム全体の概要
アルゴリズム全体としては、以下のような流れになります。
- 間引きすることを前提として、木をその分多く生成する。例えば最終的に1000本の木が欲しいようなケースでは、10000本くらいの木を生成する(※3)。
- それぞれの木について、多くのデータを使って深さの平均値を求める。
- 求めた平均値で木のリストをソートする。
- 平均値が大きい側から最終的に欲しい数の木(例えば1000本)を取得して森とする。その他の木は捨てる。
- 森を使ってアノマリ検知を行う(Isolation Forestと同じ)
つまりIsolation Forestと比べると、学習時には多くのコスト(CPU時間やメモリ等)を要しますが、評価時(アノマリ検知を実行する段階)のコストは等しくなります。
性能
Thinningの性能を実際のデータで確認してみました。使用したデータは有名なKaggleのクレジットカード詐欺のデータセットです。
このデータセットはラベル付きですが、まずラベルを隠した状態で
- Thinning有りのIsolation Forest
- Thinning無しのIsolation Forest
のそれぞれで評価してデータを「異常な順番に」並べます。次に、それぞれの(異常な順に並べた)データの最初のN個に実際に異常なデータがいくつ含まれるかを、ラベルの情報を使って数えます。つまり学習はラベルなしの教師なし学習で行い、評価をラベルの情報を使って行います。
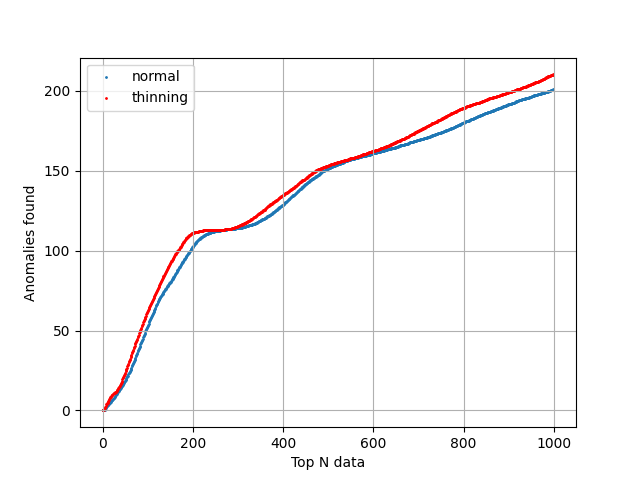
結果はこのグラフのようになりました。このグラフはそれぞれ数十回ほど実行した結果の平均値になっており、安定してこの程度の差があると言えるものになっています。異常な順に並べたデータのうち先頭の1000個の中に、本当に異常なデータは約200程度見つかっています。先頭の200個で見ると、本当に異常なデータは約100個見つかっています。
赤はThinning有りのデータで、全体を通じてThinning無しよりも多くの異常を見つけることができています。差はわずかですが、2つはほぼ同じアルゴリズムであり、また元のIsolation Forestは非常に優れたアルゴリズムなので、この程度でも性能が上昇することは非常に好ましい事だと思います。
まとめ
今回はIsolation Forestの性能をより高めることのできる、Thinningという新しい手法について紹介しました。Isolation Forestではランダムに生成したそれぞれの木について注目することはありませんでしたが、Thinningではそれぞれの木を評価して「育ちの悪い木」を捨てます。良い木のみを残して良い森とし、最終的なIsolation Forestの性能が高まるようにします。
今の時点では平均値を木の良し悪しを判定するための基準として使っていますが、Thinningの基本的な発想は「悪い木を見つけて削除し、良い木だけを残す」ということです。平均値よりも優れたやり方が見つかるかもしれないので、引き続き研究していくつもりです。
※1: こちらの記事を参照のこと
※2: 普通のIsolation Forestに比べて計算量は増えてしまうので学習コストは高くなります
※3: この値はハイパーパラメータとなります。僕が実装したソースコード中ではtreeRatioという名前の変数になっています。