技術者ブログ
クラウド型WAF「Scutum(スキュータム)」の開発者/エンジニアによるブログです。
金床“Kanatoko”をはじめとする株式会社ビットフォレストの技術チームが、“WAFを支える技術”をテーマに幅広く、不定期に更新中!
二分探索による高速なIPアドレスマッチングのアルゴリズム
はじめに
Scutumには他の多くのWAFと同じようにIPアドレスを使ったアクセス制御の仕組みが備わっています。例えば特定のネットワークからのアクセスを拒否したり、逆に特定のネットワークやアドレスからのみアクセスを許可する、という設定が可能です。
このとき、例えば「日本の国内のIPアドレスからのみアクセスを許可したい」のような要求がある場合など、数千〜数万くらいの大量のネットワークアドレスのエントリが列挙されて設定されることがあります。
実際にアクセスを制御する場面では、そのとき接続してきたある1つのIPアドレスが、上記の大量のネットワークアドレスの中の「いずれかにマッチするか、あるいはまったくマッチしないか」を高速に判定する必要があります。
Scutumではこの処理に二分探索を使うことで高速なマッチングを実現しました。今回はこのアルゴリズムを紹介します。
このアルゴリズムの要点
実際にはいくつか前処理が必要になりますが、まずは要点から説明します。制御対象となるIPアドレスの入力は、例えば次のような(ごく普通の)形式であるとします。この例では3つのエントリが存在しています。
10.0.0.0/8 192.168.1.0/24 172.16.1.0/28
それぞれのエントリについて、ネットワーク内の最初のアドレスと最後のアドレスを数値(Javaならばint)に変換して、ソートされた状態で配列に格納します。
この例ならば
10.0.0.0/8
の最初と最後のアドレスはそれぞれ
10.0.0.0 10.255.255.255
になります。それぞれをintに変換すると
167772160 184549375
になります(※1)
同じように192.168.1.0/24と172.16.1.0/28も処理し、6つの値を1つの配列に入れてソートすると、次のような配列が得られます。
[-1408237312,-1408237297,-1062731520,-1062731265,167772160,184549375]
このとき6つの値が並びます。この6つの値を数直線状にイメージします。すると、それぞれのネットワークのminとmaxが次のように交互に並ぶことになります。赤い部分はネットワーク内、それ以外はネットワーク外となります。
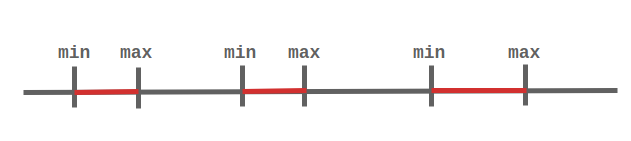
あるIPアドレスがこれらの3つのネットワークのいずれかの範囲内にあるかどうかを判定する場合、そのアドレスをintに変換し、上記配列に対して二分探索を行います。Javaの場合、Collections.binarySearchを使うことにより、探索した結果(位置)とともに、「要素そのものが検索対象のコレクションに含まれているか」についても戻り値から情報として得ることができます。
もし要素がコレクションに含まれている場合(つまり上記6つの値のいずれかと完全に一致する場合)には、いずれかのminあるいはmaxの値と検索対象のIPアドレスが一致しているということになります。この場合、結果としては「そのIPアドレスはいずれかのネットワークに含まれる」と判定します。例えば上の例で10.0.0.0や192.168.1.255などがこれにあたります。実際にはこのようなケースは少ないでしょう。
そうではなく、もし要素が検索対象のコレクションに含まれていない場合(殆どの場合はこちらになります)には、二分探索の結果、つまり対象のIPアドレスが「何番目に挿入されるべき要素なのか」が重要になります。

要素のインデックス(何番目か)に注目した場合、この図のように「ネットワーク外」「ネットワーク内」が必ず交互に並びます。そのため、二分探索の結果得られた値が偶数なのか、奇数なのかが「そのIPアドレスがいずれかのネットワークに含まれるか、含まれないか」を示すことになります(※2)。つまり二分探索の結果の値の奇/偶を見るだけで、ネットワークに含まれるかどうかがわかるのです。
これがこのアルゴリズムのキモの部分で、非常にシンプルであると言えるでしょう。計算量としてはO(logN)ということになると思います。
必要になる準備
要点は前項で説明した通りシンプルですが、実際にはいくつか下準備が必要になります。まず、ネットワークの重複の問題があります。例えば
10.0.0.0/8 10.0.1.0/24
のような入力があった場合、後者は前者に完全に内包されています。これを前項のように数直線状にプロットしてしまうとmin1-min2-max2-max1(※3)となってしまい、min/maxが交互に並ばないためにアルゴリズムは正しく動作しません。
似たケースとして
10.0.0.0/8 10.0.0.0/24
の場合はどちらのminも同じ値となっており、並べるとmin-min-max2-max1となってしまい、やはりmin/maxが交互に並びません。
これらのケースは先に処理して重複を解消する必要があります。
この解消は、例えば全てのネットワークをminに続いてmaxの優先度(SQLで言うところのorder by min, maxのイメージ)でソートしてから、順番に重複があるかを調べていく方法で行うことができます。
また、アドレスが/32で指定された場合にはminとmaxの値が同一となってしまうため、数直線状に並べて今回のアルゴリズムを適用することができません。そのため、/32で指定された(つまり単独の)IPアドレスについては、別途HashSetなどに入れておき、数直線を使うアルゴリズムとは別の場所で判定するという方法が適しています。我々の実装は最終的に
- まずHashSetを検索して、/32で指定されたいずれかのアドレスに一致するか
- 一致しない場合は、数直線に対して二分探索
という形になっています。
まとめ
今回は多数のネットワークのエントリに対してあるIPアドレスがマッチするかどうかを高速に判定するためのシンプルなアルゴリズムを紹介しました。この目的のためには他にも色々なアルゴリズムが存在するようですが(※4)、この二分探索の方法はシンプルで実装しやすく、速く、メモリ使用量もとても少ない点で優れていると考えています。
※1:この変換方法でintにすると値が負になるケースもありますが、アルゴリズム上は問題ありません
※2: この場合のJavaのCollections.binarySearchの戻り値はクセがあるので実装の際には注意が必要です。
※3: 1つめのエントリのmin/maxをそれぞれmin1/max1、2つめのエントリのmin/maxをそれぞれmin2/max2とします
※4: ルーター関係などで大量に論文があり、私はまだ全然読み切れていないです