技術者ブログ
クラウド型WAF「Scutum(スキュータム)」の開発者/エンジニアによるブログです。
金床“Kanatoko”をはじめとする株式会社ビットフォレストの技術チームが、“WAFを支える技術”をテーマに幅広く、不定期に更新中!
H2Oが自動生成したRandom Forestソースコードをハックする
はじめに
筆者が使ってみた感じ、以下のような特徴があるようです
- Javaでフルスクラッチで開発されている
- しかし、PythonやRのユーザも取り込めるように、PythonとRのインターフェースもきちんと用意されている
- 使用できるアルゴリズムの数は非常に少ないが、どれもKaggle等でよく使われる厳選されたものになっている(上画像を参照)
- そのため、「サービスやプロダクトに機械学習を実用する」という視点だと、迷いがなく非常に使いやすい
- 研究や学習向けではなく、完全に実用向き
- 学習時に並列処理が行われるので、マルチコアCPUの良さを十分に活かすことができる。(H2Oでクラスタを作成することもできるようだが、筆者はそちらは調べていない)
- OSSであるが、非常にお金がかかっている印象。UIが洗練されており、ヘルプやドキュメントも含めてとても使いやすい
- 学習の結果生成されたモデルはPOJOとして自動生成されたJavaソースコードの形でダウンロードでき、Javaプロダクトに組み込みやすい
- (H2Oと同じJava製の)WekaやRapidMiner、あるいはPythonやRなどの機械学習環境やライブラリよりも、コンセプトも設計も新しく、ビッグデータ(文字通り、非常に大量のデータ)を扱うことを当たり前のように前提にしている。
- 多くの(主に英語圏の)大企業で実績がある。PayPalの事例などがインターネット上で公開されている
- AutoML機能で、複数のアルゴリズムでのモデル生成やそれらのアンサンブルなどまで一気にやってくれる。有料となるH2O Driverless AIだとさらに凄い(特徴エンジニアリングまでやる)らしい
まだまだ日本語の情報は少なく感じますが、特にJavaのプロダクトに機械学習を導入する際には、非常に有力なソフトウェアだと思います。
POJO
ScutumではH2Oの機械学習実装の1つであるDistributed Random Forestを使っています。ScutumはJava実装であるため、H2Oが生成したモデルをPOJOのソースコードの形でダウンロードし、それを組み込んでいます。
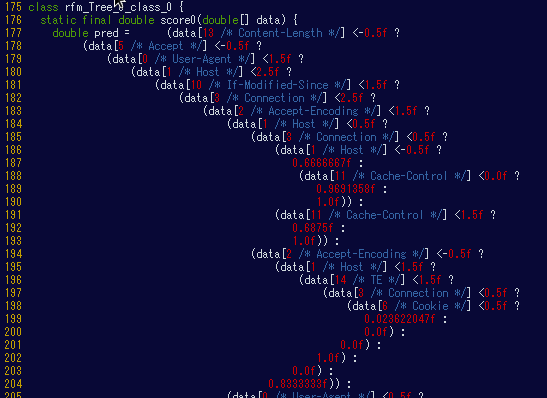
先述のようにH2Oは実用性、つまりプロダクトやサービスへの組み込みを強く意識して開発されているようです。H2O自体は巨大(約350MB)ですが、生成したPOJOはh2o-genmodel.jarという12MBのファイルのみに依存するようになっています。わざわざ「POJO」というキーワードを前面に押し出しているのも、おそらく組み込みが容易であることを伝えるためだろうと思われます。
近年では人が理解できるようなシンプルなモデルが生成されるケースは少なくなっているとは思いますが、機械学習で生成されたモデルが分類時に実際にどのように動くのかを知りたい場面はあると思います。H2Oが生成するのは何しろJavaソースコードそのものであるため、挙動は完全にトラッキング可能です。どのように動くのかを追おうと思えば、デバッガ上で1ステップずつ追うことすら可能です。(もちろん、どのくらいの手間と時間がかかるかはわかりませんが...)
モデルのブラックボックスでの納品が嫌がられるケース(万が一、不正なコードの混入事故があった場合に調査したい場合など)にも良いかもしれません。
私はプログラマであるためか、機械学習した結果のモデルをバイナリでプロダクトに載せるよりも、このようにソースコードの形で吐かれたものを組み込む方が心理的にとても気持ちよく感じました。50ノード程度のランダムフォレストでもソースコードの行数は膨大なので、実際には全部を読むことはないのですが、それでも「理解しようと思えば、理解できるはず」という安心感があります。所々を読んでみて、「なるほど、決定木がたくさんあるな...(当たり前)」などの感触を掴めると、何となくよい感じです。
パフォーマンスチューニング
ここからがハックの内容です。最初はH2Oが生成したPOJOのソースをそのまま使おうと思っていたのですが、初期に生成されたコードはやたらとDouble.isNaNが含まれていました。

最初は単に「Double.isNaNのせいで読みづらいな」と感じただけなのですが、もしかしてパフォーマンス的にもかなり無駄があるのではないか?と思い、挙動をもう少し調べてみました。
モデルを使って分類する場合には、引数として分類したい対象の特徴ベクトルを与え、関数呼び出しを行います。この特徴ベクトルの値としてDouble.NaNが含まれていないことを前提にできるのであれば、決定木中でのチェックは不要となることがわかりました。
そこで試しにすべてのisNaNのチェックを除去してみたところ、分類の速度が倍になりました。ただし、もともと非常に速い(とてもパフォーマンス的に優秀なコードが出力されている)ので、実際にはこのチューニングが必要とされるケースは少ないかもしれません。
依存性の除去
先述したようにH2Oが生成したモデルをPOJOとして組み込む場合、基本的にはh2o-genmodel.jarという12MBのファイルへの依存があります。しかしDistributed Random Forestのソースコードは非常にシンプルで外部のデータ構造などに依存している箇所が非常に少なく、このjarファイルへの依存は除去することができるのではないか?と思いつきました。12MBのjarファイルをプロダクトに同梱せずに済むことは、それなりにメリットとなるからです。結論として、これは可能でした。
依存性を除去する場合、https://h2o-release.s3.amazonaws.com/h2o/rel-turing/1/docs-website/h2o-docs/pojo-quick-start.htmlに書かれているようなRowDataクラスを使ったコードは書けなくなります。分類するためには、直接POJOのクラスのscore0という関数に、doubleの配列で特徴ベクトルを渡すことになります。そもそもRowDataクラスを使うこと自体がオーバーヘッドとなるので、これは全く問題ないと考えました。
POJOから依存性を除去するには、hex.genmode以下のパッケージに依存する部分をソースコードから取り除いていきます。import文の削除やextend部分の修正、アノテーションの削除をなどが必要になります。また、唯一呼び出されているクラス外メソッドであるhex.genmodel.GenModelクラスのgetPrediction関数をどこかに移植し、それを呼び出すように書き換えます。この関数はシンプルで外部依存がないため、簡単に移植することができます。
これらの作業は簡単で、Javaプログラマであれば、どうやればよいかすぐにわかるようなものです。
Javaアプリケーションではライブラリを使うにつれてjarファイルへの依存が多くなってしまい、だんだん全体のファイルサイズが巨大化するという悩みがあると思います。このような工夫で少しでもダイエットすることができるのはScutumのケースとしてはありがたいです。
まとめ
今回は新進気鋭の機械学習プロダクトであるH2Oの紹介と、そのモデルのソースコードをハックすることで、軽量かつ高速にプロダクトにランダムフォレストを導入した事例についてまとめました。海外では非常に盛り上がってきているH2Oを是非試してみてください。