技術者ブログ
クラウド型WAF「Scutum(スキュータム)」の開発者/エンジニアによるブログです。
金床“Kanatoko”をはじめとする株式会社ビットフォレストの技術チームが、“WAFを支える技術”をテーマに幅広く、不定期に更新中!
ベイジアンネットワークを使ったウェブ侵入検知
はじめに
私たちが提供しているSaaS型のWAFサービス、Scutum(スキュータム)では、より高精度な攻撃検知を実現するために、ベイジアンネットワークの技術を利用しています。今回は「ウェブセキュリティ」「不正検知」「異常検知」「攻撃検知」といった観点から、ベイジアンネットワークについて解説します。
ベイジアンネットワークとは?
ウィキペディアによると、ベイジアンネットワークは次のようなものです。
ベイジアンネットワーク(英: Bayesian network)は、因果関係を確率により記述するグラフィカルモデルの1つで、複雑な因果関係の推論を有向グラフ構造により表すとともに、個々の変数の関係を条件つき確率で表す確率推論のモデルである。
非常に的を射た説明ですが、「わかっている人にはわかるし、わかっていない人にはわからない」という感じもするかもしれません。基本からしっかり理解したいという場合には、まずベイズの定理を理解してしまいましょう。そうすれば、基本的なベイジアンネットワークの仕組みはすぐに理解できます。「ベイジアンネットワーク」と聞いて何やら難しそうな印象を受ける人もいるかと思いますが、中高生レベルの数学(確率)の知識で十分に理解することができるので、心配は無用です。ノード数が少ない(4,5個程度の)ネットワークであれば、電卓を使った四則演算で確率を計算することができます。
さらに進んで、ベイジアンネットワークを実用的なシーンで使おうと考える場合には、計算を高速に行うためにグラフ理論に関係する知識・技術(ジャンクションツリーアルゴリズム等)や、データに基づいたモデル構築の技術などが追加で必要になってくることがありますが、こちらはかなり高度な数学が必要となるようです(ちなみに私はこのレベルは殆ど理解できていません)。
いずれにせよ、オープンソース・商用を含め、ベイジアンネットワークを利用するためのソフトウェアライブラリは数多く存在しているので、まったく数学的な理解をせずとも、モデルを構築し、利用することは可能となっています。本エントリではベイズの定理とベイジアンネットワークの数学的な解説については省略します。詳しくは涌井良幸氏著「道具としてのベイズ統計(日本実業出版社)」などを参考にしてください。
スプリンクラーの例

それでは、ベイジアンネットワークがどのようなものなのか、簡単な例を見てみることにします。上の画像は英語版ウィキペディアに載っているものです。ベイジアンネットワークの例として有名な「スプリンクラーの例」で、それぞれのノードは「スプリンクラーが動作したかどうか」「雨が降ったかどうか」「芝が濡れているかどうか」を表しています。
ベイジアンネットワークはこの画像のように、因果関係を表すノードとエッジ、それにそれぞれのノードについて、親ノードがとる値によって構成される条件毎の確率を記述する、CPT(Conditional Probability Table)と呼ばれる表によって構成されます。(ここで、Tはtrue、Fはfalseの略です)
たとえばこの表では、「雨が降ったかどうか」のノードから、「スプリンクラーが動作したかどうか」のノードに対してエッジ(矢印)が引かれています。これは「雨が降る、あるいは降らないことが、スプリンクラーが動作するかどうかという確率に影響を及ぼす」という因果を表します。
また、具体的に「雨が降った場合にスプリンクラーが動作する確率」がそれぞれ0.01、つまり1%であることが、画像左上のCPTの最下行からわかります。スプリンクラーは雨の日に動作しても意味がないので、雨が降った日には極力動作しないようになっているようです。ここで、「このCPTに記述されている0.01や0.4などの数字の根拠はどこから来ているのか?」という疑問が浮かぶかもしれませんが、これについては後ほど解説します。
この例のベイジアンネットワークをいかにもベイジアンネットワークらしく使うのは、次のような確率を求めるときです。
「今、芝が濡れていることがわかった。さて、雨が降った確率はいくつだろうか?」
これを見て「おっ、面白いな」と感じましたでしょうか?普通の考え方であれば、因果関係の「原因」がまずあり、それに対し、ある確率に従った「結果」が伴うわけです。計算して求めるのは「結果がある値になる確率」であり、この例では、例えば「雨が降った場合に、芝が濡れている確率」のことになります。しかし、ベイズの定理あるいはベイジアンネットワークの世界では、「結果」が見えた(わかった)ときに、「原因」となる事象の値がどうであったのか、の確率を求めに行きます。
オープンソースのベイジアンネットワーク実装であるWekaのBayes Network Editorを使い、実際にこの例の計算を行ってみましょう。ダウンロードしたパッケージに含まれるweka.jarをカレントディレクトリに配置し、次のようにJavaコマンドを実行することで、エディタが起動します。
java -cp weka.jar weka.classifiers.bayes.net.GUI
商用のベイジアンネットワーク用ソフトウェアとは異なり、基本的な機能しか実装されていないため、初めて触る場合にはとてもわかりやすくなっています。ノードを追加し、それぞれのノードを右クリックして「親ノード」を追加したり、CPTに値を設定したりしていく作業を行います。CPTへの値の入力は、ツールによって縦軸と横軸が逆転したりしていてわかりにくい場合があり、注意が必要です。
作成したベイジアンネットワークはXMLファイルとして保存することができます。スプリンクラーの例をGitHubに置いておきましたので、よくわからない場合にはこちらのXMLファイルをWeka Bayesian Network Editorで開き、参考にしてください。
ネットワークを作成し、メニューから「Tools - Show Margins」を選択すると、各ノードの計算された確率が緑の字で表示されるようになります。
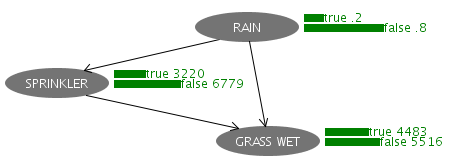
雨が降る確率は右上の「.2」の部分で、これは0.2つまり20%という意味になります。CPTの値がそのままなので、計算するまでもありません。一方でスプリンクラーの値は3220及び6779となっていますが、これは「スプリンクラーが動作する確率は約32.2%」「動作しない確率は約67.8%」という意味を表します。CPTにある値とは違う数値となっていますが、これはCPTを使って「雨が降り、かつスプリンクラーが動作する場合」ケースや「雨が降らず、かつスプリンクラーは動作する場合」などの確率を計算した結果となります。ベイズの定理を使って計算することもできますし、単純に全てのありえる場合を列挙して、それぞれの確率を計算していくことでも求めることができます。WekaのBayesian Network Editorは自動的に計算してくれるので、非常に楽にベイジアンネットワークを使うことができます。
では、芝が濡れている場合に雨が降った確率を求めてみましょう。上の画像から、芝が濡れている確率は約44.8%であることがわかりますが、今、「芝は濡れている」という情報は既に手に入ったと考えます。つまり、44.8%の確率の範囲内の出来事が起こったわけです。このように、既に起こった、あるいは判明した情報を「Evidence」や「Observation」と呼び、ベイジアンネットワークにこれらの情報を入力していくことになります。
「GRASS WET」のノードを右クリックして「Set Evidence」を選択し、値をtrueに設定します。これが「芝が濡れている」ことを意味します。するとベイズの定理に従ってネットワーク上に計算結果が伝播していき、他の2つのノードの確率の値がそれぞれ変化します。
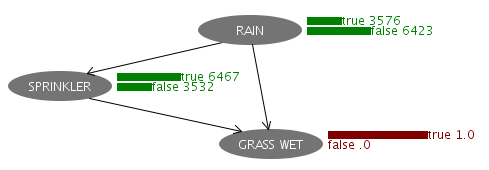
雨が降った可能性は右上の「3576」の部分で、つまり約35.8%ということになります。このように、「芝が濡れている」という情報によって、20%だった確率が35.8%に上がりました。このように、あらかじめ作成しておいたネットワーク状のモデルに対し、判明した情報を追加で入力していくことで、確率の精度を上げていくという作業がベイジアンネットワークの基本的な使い方となります。
ウェブ侵入検知でベイジアンネットワークをどう使うか?
ウェブ侵入検知の分野では、例えば原因と結果が、それぞれ「攻撃かどうか」「alertという単語がHTTPリクエストに含まれているかどうか」等の内容として、ベイジアンネットワークのノードとして表現できます。ここでは最もシンプルな形のベイジアンネットワークを考えてみます。
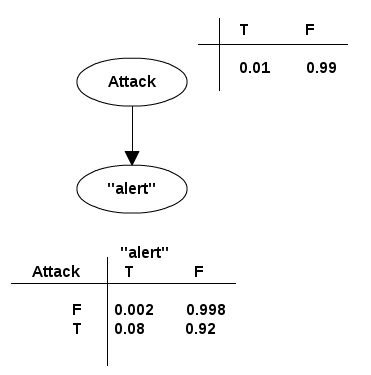
ここで大事な点として、まず「攻撃であること」という原因があり、その結果として「alertという単語がHTTPリクエストに含まれる」という事象が発生する、という順番で考えるようにします。「alertという単語があるから攻撃である」という順番では考えません。この因果の向きは比較的混同しやすいポイントです。
やや冗長になりますが、このベイジアンネットワークに記述されている意味を文章として書いてみると、次のようになります。
- HTTPリクエストが攻撃である確率は、1%である
- HTTPリクエストが攻撃でない確率は、99%である
- HTTPリクエストが攻撃である場合に、そのHTTPリクエストがalertという文字列を含む確率は、8%である
- HTTPリクエストが攻撃である場合に、そのHTTPリクエストがalertという文字列を含まない確率は、92%である
- HTTPリクエストが攻撃でない場合に、そのHTTPリクエストがalertという文字列を含む確率は、0.2%である
- HTTPリクエストが攻撃でない場合に、そのHTTPリクエストがalertという文字列を含まない確率は、99.8%である
Wekaを使ってこのモデルを作成すると、次のようになります。何も追加の情報がない場合には、HTTPリクエストにalertという文字列が含まれる確率は約2.7%であることがわかります。
ウェブ侵入検知を行う立場から考えた場合、私たちが知りたいのは、次の質問に対する答えです。
今、目の前にあるHTTPリクエストが攻撃である確率はいくつか?
答えは既に上に書かれているとおり、1%です。
しかし、これではもちろん何も面白くありません。というのは、alertノードをまったく使っていないからです。ベイジアンネットワークが面白くなるのはここからです。我々は侵入検知をする側であり、HTTPリクエストがどのような内容なのかについては確実に知ることができると考えて良いでしょう。そのため、「HTTPリクエストがalertという文字列を含むかどうか」については、確率ではなく、確証として真あるいは偽の値を得ることができます。仮にalertという文字列が含まれていたとすれば、上記の質問は以下のように変化します。
今、目の前にあるHTTPリクエストにalertという文字列が含まれていた。 このHTTPリクエストが攻撃である確率はいくつか?
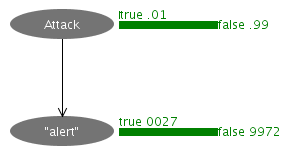
alertノードのevidenceをtrueにセットすると、モデルは次のように変化します。
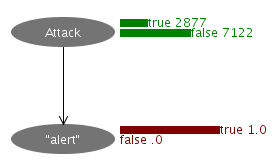
HTTPリクエストが攻撃である確率は、1%から約28.8%へと大幅に増加しました。このように、侵入検知でベイジアンネットワークを使う場合、「観察可能なノード」に値をセットすることで、直接観察することはできない、そして本当に知りたいノードの確率について、情報を得るという操作を行っていくことになります。前者の「観察可能であること」がわかっているノード(この例では"alert")のことをInformation variable、そして後者の、求める目的となる、直接観察することはできないとわかっているノード(この例ではAttack)のことをProblem variableと呼ぶ場合もあるようです(この呼び方はモデルを作成する際の単なる分類にすぎず、ベイジアンネットワーク上での計算では区別されません)。
この例はわずか2ノードの非常に単純な例であるため、もちろん実用レベルのモデルとは言えませんが、なんとなく感触が得られたのではないでしょうか。
スパムフィルタとナイーヴベイズ
情報セキュリティの分野とベイズ理論の出会いとして一番有名なのはスパムメール対策として用いられるベイジアンフィルタでしょう。これはナイーヴベイズと呼ばれる非常にシンプルな形状のベイジアンネットワークを使うもので、前項の2ノードの例もこのタイプと考えることができます。
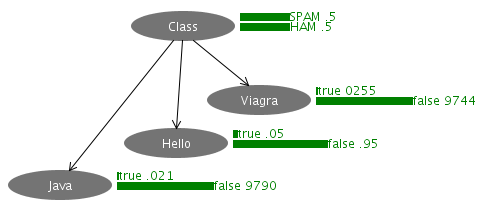
これはJava、Hello、Viagraの3つの単語について、それぞれがメール本文に登場したかどうかの有無を変数とするナイーヴベイズです。GitHubからXMLファイルをダウンロード可能です。「Java」という単語が見つかった場合にClassノードのSPAMの確率がいくつに変わるか、などを是非、実際に試してみてください。
このように、スパムフィルタとして使われるベイジアンネットワークは、前項のAttackとalertによって構成されたネットワークとほぼ同じ構造をしています。最終的に知りたいノードであるClassノードがただ一つの親ノードとなっており、それに複数の子ノードがぶらさがっている形になります。実際のスパムフィルタでは子ノードの数は数多くの英単語それぞれに当てはめられるため、数千や数万以上になるでしょう。
多くのナイーヴベイズを使ったスパムフィルタでは、それぞれのノードは単純に「ある単語がメール本文中に登場したかどうか」を、いわば(機械学習などにおける)「特徴」として使用します。そのため各ノードはそれぞれの単語と一対一の関係になります。しかしナイーヴベイズの形状をしたベイジアンネットワークでは、それぞれのノードについて「単語の有無以外の特徴」を使用することも、もちろん可能です。例えば「電話番号の有無」や「メール本文が10行以上かどうか」などを1つのノードとすることもできます。
スパムフィルタではなくWAFにおいても、この「特徴の選び方」が優れていれば、ベイジアンネットワークの構造そのものはナイーヴベイズのように単純であっても、高精度で攻撃を分類可能なモデルを作ることができる可能性は十分にあると思われます。しかし、私たちのモデルはナイーヴベイズよりも少しだけ階層が深いモデルを使用することにしています。この理由は後述します。
CPTの値はどのように決定されるのか?
ベイジアンネットワークではグラフィカルなネットワークの形状そのものに目を奪われがちですが、それぞれのノードの確率を記述するCPTの中身も非常に大きな意味を持ちます。本エントリ中、ここまで一切説明してきませんでしたが、このCPTの値はどのように決定されるのでしょうか?
実は、答えは「なんでもあり」です。値は、専門家(エキスパート)が経験に基づいて一切の裏付けなしに「適当に」決めてしまう場合もありますし、また逆に、裏付けとなるようなデータが(いわゆるビッグデータ的に)大量にある場合には、そこから別の技術などを使って統計的に集計した、裏付けの高い数値を使うこともできます。例えばスパムフィルタでは、ユーザがスパムメールを受け取るたびに、そのデータが活かされてCPTの値が更新されていきます。
ベイジアンネットワークのモデル側の視点で考えた場合、CPTの値は単なる数字に過ぎないので、その数字に裏付けがあるのか無いのかという点は、モデルが確率を計算する段階では一切考慮されません。適切なCPTの値であれば、モデルはうまく動作するでしょうし、そうでない場合には的外れな答えを返すだけです。
商用のベイジアンネットワークソフトウェアなどではデータからネットワーク構造とCPTの中身の両方を含めたモデルを自動的に生成してくれるものもあるようです。
ScutumのWAFとしての検知性能向上に向けた挑戦
Scutumは元々はシンプルなシグネチャベースのWAFとしてスタートしました。「ブラックリスト方式」とも呼ばれる、いわゆる「悪い特徴に注目する」仕組みです。ブラックリスト方式の最も原始的な動作の例として、例えば「HTTPリクエスト中にalertという単語があったらブロックする」というものが考えられるでしょう。この場合、そこには「90%の確率で攻撃である」のような確率的な考え方は存在せず、ばっさり善か悪かを区別するようなイメージになります。
この方法には次のようなメリットがあります。
- 挙動が明確であり、予期せぬ動作をする可能性がない
- パフォーマンスが一定で、比較的高速である
- 人間が容易に挙動を変更することができる
そして、次のような見逃せないデメリットがあります。
- 誤検知してしまう確率がとても高い(検知精度が低い)
このように見逃せないデメリットを抱えているので、私たちはより高い検知精度を求めて別のアイデアを試すことにしました。そして採用したのが、「複数の特徴にそれぞれ重み付けを行い、全体のスコアが閾値を超えたら攻撃とみなす」というもの(以下、閾値モデル)です。例えば「alertという単語があったら8点加算」「scriptという単語があったら5点加算」のようにしてそれぞれの特徴にしたがって計算し、全体が15点を超えたら攻撃と判断する、というようなものが考えられます(実際にはもっと複雑なルールになります)。このとき、正常な通信に多く見られる特徴では加算ではなく減算する、という考えも採り入れることで、単純なブラックリスト方式に比べ、検知精度を大幅に向上させることができました。
ここで(それなりに)解決したのは、上記のブラックリスト方式のデメリットである「誤検知してしまう確率がとても高い」という点です。WAFにとって誤検知しないこと、つまり検知精度が高いことは、致命的といって良いほどに重要なポイントです。その検知精度が上がったのですがら、とりあえずは大成功と言える成果であり、開発チームとしてはこの成果についてかなり満足していました。
しかし一方で、この閾値モデルにしたことで「挙動の変更が難しくなる」という別の問題を抱えることになりました。ある特徴の重みを変更すると、その影響で、今までなら止めていた攻撃が止まらなくなったり、あるいはその逆が起こってしまうのです。特に問題だったのは人間(いわゆるエキスパート)の勘との不一致です。「この特徴の重み(重要度)はこのくらいだろう」というような感覚に基づいてスコアを決定していっても、どうしても全体としての整合性が取れない、あるいはとても取りにくいという問題が起こりました。
この問題はとりあえず、テストデータ(止めるべきものと止めてはいけないもの)に基づいて遺伝的アルゴリズムを使い、コンピュータに自動的に各特徴ごとの重み付けの作業を行わせることで、とりあえずは落ち着かせました。しかしその後しばらくすると、そもそも「怪しい特徴があれば加算する」「怪しくない特徴があれば減算する」というのでは、あまりにも単純すぎるのではないかという考えが浮かび、これが長い期間私の脳裏から離れずに、より良いアイデアはないか、と模索するモチベーションとなりました。
ベイジアンネットワークによりWAFの検知精度を大幅に向上させる
そんな問題意識の中、ビッグデータブームなどもあり、データサイエンス系の書籍を読み漁っていたところ、ベイジアンネットワークこそがまさにこの用途に最適なのではないだろうかという考えに至りました。そしてWekaを使った実装を実際にWAFに組み込んでテストしてみました。
その結果、かつては「シグネチャ」として、ひとつひとつ別に扱っていたそれぞれの特徴をベイジアンネットワークの各ノードとし、またそれぞれの特徴を適切な数の親ノードの下にまとめることで、前項で示した閾値モデルが抱えていた問題が解決され、また同時に検知精度が閾値モデルのものよりも大幅に向上することがわかりました。閾値モデルを開発する際にはチューニングを完了するまでにかなりの時間を必要としたのですが、ベイジアンネットワークモデルは非常に短期間で納得のいくレベルにまでチューニングを行うことができたというのも大きな驚きでした。現状、手作業によるチューニングで思うとおりにモデルの挙動をコントロールできているため、閾値モデルで行ったような遺伝的アルゴリズムを使った自動チューニングは行っていません。
この、ベイジアンネットワークモデルが非常にうまく動作することの理由について考察を行ってみました。
単純な二方向の計算ではないこと
閾値モデルでは、各特徴に割り当てられた正または負のスコアは単純に「善」か「悪」かを表しており、つまり非常に単純な二方向のみの計算が行われていました。「ある特徴のスコアを変更すると、それが必ず全体に同じ度合いで波及する」ことになってしまい、これがまさにモデル全体としての挙動の変更が難しくなったことの理由でした。
考えてみれば、専門家(エキスパート)があるHTTPリクエストが攻撃かどうかを判定する際のプロセスは、それほど単純ではありません。最終的には「攻撃かどうか」の結論を出すことになりますが、その前に、多くの視点からそのHTTPリクエストを観察するのが普通です。例えば次のような色々な見方があり得るでしょう。
- どんなドキュメントを取得しようとしているのか
- サーバ側に情報を送ってきているPOSTリクエストかどうか
- ファイルのアップロードかどうか
- HTMLをパラメータに多く含んでいるようだが、CMSアプリケーションを正規に利用しているユーザだろうか
- ボットによって自動的に送られてきたHTTPリクエストかどうか
- やけに同じIPアドレスから攻撃が連続しているが、脆弱性検査だろうか
- ガラケーからのリクエストかどうか
上に挙げた例だけでもわかるように、HTTPリクエストが持つ性質は、単純に「善」「悪」ではなく、さまざまな属性に分類されていくものになります。中には複数の属性に同時に属するものもあるでしょうし、その程度、度合いもさまざまなレベルにばらつくことになるでしょう。
攻撃について考えた場合、例えばXSSやSQLインジェクションなど、さまざまな属性が存在します。仮に出来の悪い閾値モデルが「scriptという単語があったら5点加算」「UNIONという単語があったら8点加算」のように動作する場合、「script union」という内容のHTTPリクエストが来た場合には13点として計算してしまいますが、もちろんXSSとSQLインジェクションが同時に起こる可能性は低いため、これは不適切な計算処理であることがわかるかと思います。単純な二方向での計算ではなく、「XSSとして考えた場合のスコア」「SQLインジェクションとして考えた場合のスコア」のように、属性ごとに分けて計算するべきでしょう。
閾値モデルではなくベイジアンネットワークを使うことで、この問題はほぼ完璧に解決します。上に列挙した例のようなそれぞれの属性についてノードを作成し、そのノードについて子ノードとして特徴を追加していきます。例えば「multipartなリクエストである」というノードは、「ファイルのアップロード」というノードの子ノードになるでしょう。
このようにベイジアンネットワークを使って多数の、複雑に絡み合う属性それぞれについて同時に確率を計算することができるようになります。「XSSである確率が約10%あるが、CMSを使ったウェブページの更新のためのHTTPリクエストである確率が約40%あるので、これは攻撃ではないだろう」というようなことがわかるようになるのです。
確率(乗算)で表現できること
閾値モデルでは単純な加算・減算のみを行います。そのため、例えば「union select」という文字列に対して「unionが見つかったので5点加算」「selectが見つかったので5点加算」となり、合計10点加算するような動作となります。しかし、selectとunionの両方が見つかるケースというのは確率的にはとても低く、かつ危険性は高いものであり、10点というイメージではなく、30点くらいの危険性のイメージになります。これを表現するには、以下のようにルールを決める必要があります。
- selectが見つかったら5点加算
- unionが見つかったら5点加算
- unionとselectの両方が見つかったら20点加算
このように複数の特徴の組み合わせを考慮する必要がでてきてしまうと、ルールの数が増えてしまい、チューニングがしずらくなるという問題が発生します。この問題の根本的な原因は確率で考えていないことです。スコアの算出には加算・減算よりも、むしろ乗算が使われるべきではないか?というのが、長い間私が抱いていた疑問のひとつでした。ベイジアンネットワークはまさにこの疑問に対する答えとなるわけです。
視覚的に操作できること
前項の内容とも関係がありますが、「HTTPリクエストがどのようなものなのか」を考える場合、複雑な属性やそれぞれの属性を裏付けるような特徴が複雑に入り組んだ関係を持つことになります。これを直接プログラミングによってコードに落とし込むのは非常に難しく、また、仮にできたとしても、ソースコードからその複雑な関係性を読み取ることは困難になってしまうでしょう。
しかしWekaのBayesian Network Editorを使って直接、視覚的にモデルを作成し操作することによって、この問題は解決します。さまざまに入り組む複雑な関係性を、エキスパートの知識そのままの形でコンピュータが処理可能な形に落とし込むことができるのです。
チューニングが容易であること
ベイジアンネットワークではネットワークの構造に従って必要がある箇所にだけ計算結果が伝播されます。そのため、閾値モデルが持っていた「ある変更がすぐに全体に直接影響を及ぼしてしまう」という問題が解決します。
ある特徴の確率を手作業で調整する(CPTの値を変更する)ことによって起こる影響が予想しやすく、コントローラブルです。モデル作成後にデータを使ったテストを行い、その結果を受けてCPTの値を調整したり、場合によってはネットワークの構造を変えたり、というチューニング作業が非常にスムーズに進みます。ベイジアンネットワークを導入しようと考えついたときには、このようなメリットがあることは予想していなかったため、この点は非常にうれしい驚きでした。
「Mediating Variables」とも呼ばれる中間層的な役目を果たすノードを積極的に追加していくことで、このチューニング作業がとてもやりやすくなります。
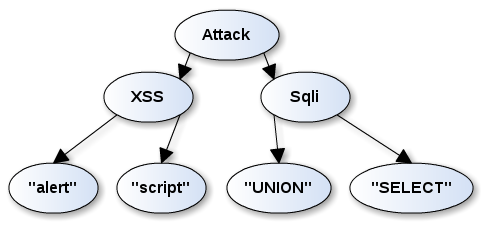
上図の例ではXSSとSqliの2つのノードがMediating Variablesの役目を持ちます。alertノードやscriptノードのCPTを調整するとXSSノードにどの程度の影響が出るかを見ることで、チューニングがやりやすくなります。もしXSSノードとSqliノードが存在しない場合、ネットワークはナイーヴベイズ型になりますが、そうなると個々のノードの調整がすぐに全体に影響を及ぼすようになってしまいます(実際のネットワークはもっと複雑です)。
ベイジアンネットワークはニューラルネットワークのようなブラックボックス型のモデルとは異なり、人間がその意味を明確に読み取ることができます(ただし、大規模なネットワークでは難しくなります)。細かい調整を施すことが可能であり、エキスパートがこつこつと性能を上げていくことができます。
人間の意志決定のプロセスと非常に似ていること
ベイジアンネットワークを使った確率の計算は、人間が意志決定する際のプロセスに非常に似ているとする意見がありますが、私もその通りだと感じます。複数の複雑に入り組んだ属性や特徴が事前に知識(モデル)として存在しており、それに対して、「今回、判明したこと」を追加情報として(evidenceとして)入力していくことで、最終的な意志決定を行うというのは、まさに普段我々が行っていることではないかと感じます。
「エキスパートが目で見れば、そのHTTPリクエストが攻撃であるかどうか、かなり確実に判定することができる」という前提がある場合、それをコンピュータに落とし込むことを考えると、ベイジアンネットワークのように、人間が意志決定するプロセスを自然にモデルの形にできるものが適切な技術として選択されるべきだと考えます。
機械学習との関係は?
前項まで私たちの提供するSaaS型WAF、Scutumにおけるベイジアンネットワークの役割について説明してきましたが、ベイジアンネットワークについて調べる過程で私が個人的に持っていたいくつかの疑問についても簡単に触れておきます。まず、「ベイジアンネットワークと機械学習の関係」についてです。
ベイジアンネットワークはノードとエッジ、そしてCPTによって表現されるものであり、それを機械(コンピュータ)が生成することも、人間が作成することもどちらも可能です。実際にさまざまな事例の情報を見てみた感じでは、この両方が使われているようです(私たちのWAFでは、人間が作成する、数十〜百程度のノードによって構成されるネットワークを使っています)。千や万といった単位のノードを扱うネットワークを考える場合には、人間が手作業で管理するのは現実的ではないので、機械学習によるネットワークの自動生成が用いられるでしょう。また、先に紹介したスパムフィルタもシンプルな形態をしたベイジアンネットワークが自動的に構成されるという意味では、この分類に属します。
また、おそらく「ネットワーク自体は人間が手作業で作り、CPTの値は(大量の)データに基づいて機械学習させる」というアプローチも有効であろうと思います。こちらについてはあまりきちんと調査できていません。
ベイジアンネットワークの計算コストは他の手法と比べ高いと考えられており、ノード数が多い場合にはグラフ理論などに基づいて効率的に計算を行うなどの工夫がなされるケースが多いようです。
ノードはカテゴリ変数の形しか取ることができないのか?
答えはNoのようです。ベイジアンネットワークの例として出てくるもの(スプリンクラーやバーグラーアラームなど)の殆どが、各ノードについてtrue/falseなどのカテゴリ変数を用いるものですが、実際のソリューションのためにベイジアンネットワークを使い始めると、ノードに数値型の変数を使いたくなるケースが出てくるのが自然です。Risk Assessment and Decision Analysis with Bayesian Networksという本の9章に詳しい解説があるので、興味がある方は参考にしてみてください。
残念ながらWekaのBayesian Network Editorでは、カテゴリ変数しかサポートされていないようです。
ベイジアンネットワークと侵入検知の分野の関係は?
ベイジアンネットワークの応用範囲は非常に広く、個人的には「人間(エキスパート)ならばうまく判断できることを、コンピュータにも同じように判断させたい」というケースであればどこででも使えるのではないかと思います。WAFに限らずネットワーク型IDSやホスト型IDSにおいてもベイジアンネットワークの利用は研究されており、やはり私たちと同様に「観測された特徴から確率を計算して最終的に侵入かどうかを判定する」という形で使われているようです。検索で見つかるのは殆どが研究論文なので、私たちのように商用のサービスで実際に使っているケースはまだまだ少ないように見えます。
ところで、Googleで"bayesian network" "intrusion detection"で検索すると5万件ほどヒットするのに対し、日本語で"ベイジアンネットワーク" "侵入検知"で検索してもわずか600件程度しかヒットしません。このテーマについては日本と海外とで大きな開きがあるようです。
今後の展望
これまで説明してきたように、Scutumにとって検知エンジンのコア部分にベイジアンネットワークを用いるというアイデアは革命的なインパクトをもたらすものでした。しかしまだ全体がベイジアンネットワーク化されたわけではなく、閾値モデルを採用している箇所もあります。また、もちろん単純なシグネチャのみで判定する箇所も残っています。これらは適材適所的に使い分けていく予定です。
ベイジアンネットワークには、いくつかの異なる判定基準をまとめる、糊(のり)としての役割を持たせることも可能です。例えば閾値モデルが出す判定結果をひとつのノードとし、さらに他の検知の仕組みの判定結果を別のノードとして、それぞれの信頼性に基づいたCPTを作成して、統合的に判断を下すためにも使えます。今後もより高い検知精度を目指し、ベイジアンネットワークに限らずデータサイエンスの分野の技術を研究し、投入していく予定です。
カンファレンスのご案内
2月にAVTokyoで、そして3月にOWASP APACでWAFの技術に関連した講演を行います。興味がある方、ぜひご参加ください。
一緒にウェブ侵入検知をやりませんか?
Scutumの開発を行っている株式会社ビットフォレストでは、ゆったりとしたペースでウェブセキュリティの研究チームを増強中です。もしウェブ侵入検知の技術に興味があり、就職や転職を考えている方がいらっしゃいましたら、ぜひお気軽にお話をさせていただければと思います。現時点ではウェブ上に具体的な募集要項をまとめているわけではありませんので、@kinyukaにメッセージいただければ幸いです。また、上記カンファレンスの会場などでも気軽に捕まえていただければと思います。