技術者ブログ
クラウド型WAF「Scutum(スキュータム)」の開発者/エンジニアによるブログです。
金床“Kanatoko”をはじめとする株式会社ビットフォレストの技術チームが、“WAFを支える技術”をテーマに幅広く、不定期に更新中!
Java製のWAFを高速化する、7つのパフォーマンスチューニングテクニック
はじめに
私たちが提供しているSaaS型のWAFサービス「Scutum(スキュータム)」のコア部分は、Javaで書かれています。かつてJavaアプリケーションは遅いとされていた時代もありましたが、近年のJVM(Java Virtual Machine)の性能の進化は凄まじく、今では逆に「Javaは速い」と言われるようになりました。事実、現在ではJavaアプリケーションはCやC++で書かれたアプリケーションとも対等に渡り合えるほど十分高速に動作し、また同時に安定性も非常に高くなっています。
私たちはこのJVMの進化という恩恵を授かっているおかげで基本的には大きなパフォーマンストラブルには見舞われたことはありませんが、「もう少し性能が出したい」と感じる場面に遭遇することはあります。今回は、Scutumにおいて今までに実施した、Javaアプリケーションのパフォーマンスチューニングについて、いくつかを簡単に紹介したいと思います。
その1:正規表現のチューニング
Scutumではこちらのエントリで紹介したような、攻撃種別に合わせた独自の解析エンジンを使った検知と、シグネチャベースの検知の両方を組み合わせてWAFの機能を実現しています。フリーのWAFとして知られるmod_securityや、あるいはIDSであるSnortなどでもそうですが、シグネチャベースで攻撃の検知を行う場合には、よく正規表現が使われます。Scutumでもシグネチャマッチングでは基本的に正規表現を用いています。Javaではバージョン1.4以降、標準ライブラリにjava.util.regexパッケージが追加されているため、言語内で非常に手軽に正規表現による文字列マッチングを行うことができます。
正規表現では、目的を達成するための書き方は必ずしも1通りではありません。例えば文中に「SELECT」という単語が含まれているかどうかを知りたい場合には以下のように記述することが考えられます。
\W+SELECT\W+
これは例えば「SELECTION」にはマッチせず、正しく目的を達成します。しかし、上記の記述はまれにパフォーマンス上のトラブルを起こすことがあります。ポイントは『+』の使い方です。一番左に『\W+』がありますが、マッチング対象の文字列が数MB以上あり、さらにほとんどアルファベットや数字を含んでいない場合などには、この『\W+』にマッチする部分のサイズが長くなってしまい、結果として余計にCPUサイクルを消費してしまいます。ここでの目的は単に「SELECT」という単語があるかどうかを知りたいだけなので、上記正規表現を次のように書き換えることを考えます。
\WSELECT\W
このようにするとアルファベットや数字以外の文字の連続に対しても無駄にCPUサイクルを消費することがなくなり、結果として処理が高速になります。これは以下のようなコードで検証することができます。
//--------------------------------------------------------------------------------
public static String getRandomStr()
{
byte[] buffer = new byte[ 1024 * 80 ];
Random r = new Random();
r.nextBytes( buffer );
String s = new String( buffer );
return s;
}
//---------------------------------------------------------------------
public static void main( String[] args )
throws Exception
{
int count = 1000;
{
long start = System.currentTimeMillis();
Pattern pattern1 = Pattern.compile( "\\W+select\\W+" );
for( int i = 0; i < count; ++i )
{
pattern1.matcher( getRandomStr() ).find();
}
System.out.println( "pattern1:" + ( (double)( System.currentTimeMillis() - start ) / count ) );
}
{
long start = System.currentTimeMillis();
Pattern pattern2 = Pattern.compile( "\\Wselect\\W" );
for( int i = 0; i < count; ++i )
{
pattern2.matcher( getRandomStr() ).find();
}
System.out.println( "pattern2:" + ( (double)( System.currentTimeMillis() - start ) / count ) );
}
//--------------------------------------------------------------------------------
このような正規表現のチューニングによって、処理が10倍以上高速になることもあります。『+』は本当に必要なときのみ使うようにしましょう。また、シグネチャマッチングのように正規表現が使用される処理については、日常的にパフォーマンス監視の対象としておくことで、問題の発見に繋がります。
その2:正規表現エンジンの入れ替え(失敗)
先述したようにJavaには標準ライブラリに正規表現が含まれていますが、サードパーティ製の正規表現ライブラリも多数存在しています。中には「標準のものよりも高速である」と謳っているものがあるため、それらの評価をしてみましたが、結論から書くと、標準ライブラリのものが最速でした。そのため、筆者の「正規表現エンジンを取り替えて、爆速のシグネチャマッチングを実現!」という夢ははかなく消えていきました。
なお、サードパーティ製正規表現ライブラリの多くはJavaコードの書き直しを要求するものが多いため(標準ライブラリのPatternクラスやMatcherクラスが、そもそもインターフェース的ではなく、どうしても書き換えを要求する作りになっている面もありますが)、ライブラリだけ取り替えて手軽に実装を乗り換え...というわけにもいかなさそうでした。
その3:正規表現を避ける
上記「その1」において『SELECT』という単語を検出するために『\WSELECT\W』という正規表現を用いました。このように正規表現を使うことで、『SELECTION』や『DESELECT』のような紛らわしい単語にはマッチせず、目的を達成することができます。上記「その1」のように正規表現のチューニングを終えてしまったら、それ以上できることはないのでしょうか?
WAFでは常に大量のHTTPリクエストやレスポンスに対するシグネチャマッチングが行われており、その合計の負荷がCPUに響いてきます。そのため、それぞれのシグネチャマッチングにおいて無駄な処理を極力避けることが重要になります。ここで、ちょっと発想を転換してみることで、システム全体におけるシグネチャマッチングの負荷を、結果として減らすことができる例を紹介します。
文字列の検索においては、上記の『\WSELECT\W』のように非常にシンプルなものであっても、正規表現エンジンを使うのと、単純にStringクラスのindexOfのような関数を使うのとでは必要とされるリソースが異なります。もちろんStringクラスのindexOfを使う方法では、前述したような『SELECTION』や『DESELECT』などにもヒットしてしまうので、そもそも目的を達成することができませんが、とりあえずここではこの点について目をつぶり、パフォーマンス差に注目します。
単純に『SELECT』という文字列(単語ではない)が検索対象のデータに含まれているかを調べる場合、正規表現エンジンを使うのと、Stringクラスの関数を使うのでは、後者が5〜6割ほど速いようです。これは先ほど示したコードに加えて下記ブロックを実行してみることでわかります。
{
long start = System.currentTimeMillis();
for( int i = 0; i < count; ++i )
{
getRandomStr().indexOf( "select" );
}
System.out.println( "indexOf:" + ( (double)( System.currentTimeMillis() - start ) / count ) );
}
そこで、次のような方法を考えます。まずindexOfを用いて「単語であるかどうかは気にせず、SELECTという文字列が含まれるかどうか」を高速に検索します。もし含まれていないならば、正規表現『\WSELECT\W』によるマッチングは行う必要がありません。重い正規表現エンジンの出番はなく、実に素早く処理を終えることができます。
残念ながらindexOfによる検索によって『SELECT』という文字列が含まれていることが判明すれば、続けて正規表現エンジンを使い、改めてマッチングを行います。この場合、indexOfと正規表現エンジンによって二重に検索処理を行ってしまうことになるので、結果として「はじめから正規表現エンジンを使うほうがマシだった...」ということになってしまいますが、これはトレードオフということで仕方がないと考えます。
このアプローチを使うべきかどうかは、『SELECT』が検索対象のデータに頻繁に登場するのかどうか、という点から判断します。検索対象の文字列が普段ほとんど登場しないのであれば、まずindexOfで調べるというアプローチは結果として非常に有効になるわけです。
この「まずindexOfで検査し、不要な正規表現マッチングをできるだけ避ける」というテクニックは結果として目を見張るほどの負荷低減に繋がり、Scutumで最も効果を上げたパフォーマンスチューニングテクニックのひとつとなっています。上記コード例ではStringクラスのindexOfを呼び出していますが、実際に私たちが使っている実装では、大文字と小文字を区別しないindexOfを(標準のStringクラスの実装をほぼそのままコピーですが)自前で実装し、それを使用しています。
さらに改善するテクニックとして「indexOfがマッチしたら、その周辺をsubstringとして取り出し、それに対して正規表現マッチングをかける」という事も考えつきましたが、これについてはまだ評価していません。上記のテクニックが十分成果をあげたことと、正規表現の内容によってはsubstringで取り出すという方法が適さないパターンがありそうなことが、その理由となっています。
その4:文字列検索アルゴリズムの変更(失敗)
「データ構造とアルゴリズム」といったタイトルの本が数多く出版されていますが、その中でよく触れられるのが、文字列検索のアルゴリズムです。単純に頭から1文字ずつ検索する方法(ブルートフォース)よりも(場合によっては)高速である「KMP法」「BM法」などが知られています。Javaの標準ライブラリに含まれるStringクラスのindexOfの実装はブルートフォースであるため、単純な文字列検索では十分高速ですが、検索対象の文字列のサイズによってはKMP法やBM法などが高速になる可能性は十分あります。
Scutumでは上記「その3」の方法を採用したため、文字列検索をさらに高速化することができれば、シグネチャマッチングをより低負荷で実現できるはずです。そこでJavaで各種の文字列検索アルゴリズムを実装したライブラリをこちらから拝借し、パフォーマンステストを行ってみました。
結果は残念ながら(?)、Scutumで行うような短い文字列のマッチングにおいては、デフォルトのJava実装のようなブルートフォースが最速であるという結果になりました。検索対象文字列が長くなれば、他の方法がより高速になります。ブルートフォースでの検索はメモリ消費の少なさという意味でも優秀であるため、Scutumでは単純なこの方法を引き続き使うことになりました。
その5:結果をキャッシュする
「その4」まではすべてシグネチャマッチングに関するパフォーマンスチューニングでしたが、ここからはIPアドレスのマッチングに関するものとなります。Scutumでは管理画面からIPアドレスによるシンプルなアクセス制限ができます。特定のIPアドレスからのアクセスを拒否(ブラックリスト)したり、あるいは逆に特定のIPアドレスからしか接続できないようにする(ホワイトリスト)ことができます。これはWAFというよりも、一般的なファイアウォールに近い機能と言えます。
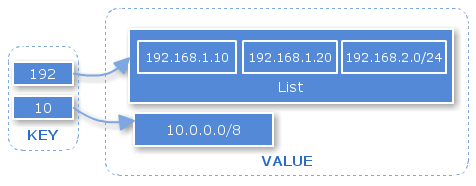
このブラックリストあるいはホワイトリストとして使われるIPアドレスのリストは、アドレスそのものや、ネットマスク表記をした形で記述することになります。以下に例を示します。
192.168.1.10 192.168.1.20 192.168.2.0/24 10.0.0.0/8
当初この機能において、IPアドレスリストは、せいぜい十数個から数十個程度のエントリがされるだろうと何となく想定しており、この部分でパフォーマンス的な問題が発生するとは予想していませんでした(これはいわゆる「そんなにたくさんのデータが入るとは...」というバッファオーバーフロー的脆弱性に繋がりかねない発想であり、我々として反省すべき点です)。
顧客数が増えるにつれこの機能は広く利用されることになり、ある日あるサーバにおいて、予想しないCPU負荷が発生していることに気がつきました。原因はあるお客様が数千のIPアドレスリストを入力されたことでした。どうやら目的は国別のアクセス制限を行うことのようで、APNICなどが提供しているような国別のIPアドレスレンジのデータベースを、どーんとこの管理画面から投入されたようです。
当初この部分の実装のアルゴリズムは単純なもので、ScutumにアクセスしてきたクライアントのIPアドレスに対し、IPアドレスリストの先頭から1つずつ、順番にマッチするかどうかを調べていくというものでした。そのため、IPアドレスリストに数千のアイテムが含まれている場合、仮にリスト中のどのアイテムにもマッチしない場合には、数千回の無駄な処理を行うことになり、非常に非効率的です。特にネットマスク表記のアイテムについては単純な文字列マッチングよりも複雑な処理が行われるため、その負荷はバカになりません。特に大きなパフォーマンス劣化には繋がらなかったものの、慢性的にCPU使用率が高い状態となったことから、急遽チューニングを施すことになりました。
あるIPアドレスに対して、IPアドレスリストに対してマッチングを行った結果を、LRU(Least Recently Used)型のキャッシュに格納することにしました。JavaではLinkedHashMapクラスを利用して手軽にLRUキャッシュを実装することができます。結果をキャッシュすることで、次回同じアドレスからリクエストがあった際には、IPアドレスリストとのマッチングを行うことなく、すぐに結果を知ることができます。この方法の場合、IPアドレスリストが更新された場合には、キャッシュはすべて破棄しなくてはなりません。
このチューニングによって大幅にCPU使用率が下がったことから、しばらくはこの形での運用を行いました。
その6:インデックス化する
「その5」で紹介したキャッシュを利用する方法で目的のパフォーマンスは達成していたのですが、キャッシュはメモリを圧迫すること、そしてキャッシュされていない、最初のアクセス時の計算量にまだまだ無駄があることから、より効率的な実装に切り替えることにしました。
IPアドレスリストの各アイテムではネットマスク表記が可能ですが、Scutumの管理画面ではネットマスクの値には8〜32という制限が存在しており、例えば『10.0.0.0/7』のような記述は管理画面において入力エラーとなり、使用できません。そのため、一番左の第一オクテット目を見るだけで、ある程度マッチするかどうかがわかる状態となっています。例えば次のようなリストの場合を考えます。
192.168.1.10 192.168.1.20 192.168.2.0/24 10.0.0.0/8
上記リストでは第一オクテットの値は『192』と『10』しか存在していません。そのため、例えば『172.16.1.1』のような値は、第一オクテットの値が『172』となっており、このリスト中のアイテムにはマッチしないことがすぐにわかります。この点に注目し、第一オクテットをいわゆるインデックスとして使用する実装を行ってみました。
IPアドレスリストの各アイテムについて、第一オクテットの値をキーに、そしてアイテム全体の値(192.168.1.10など)をバリューにして、ハッシュマップに格納することを考えます。このようにすることで、マッチング時には第一オクテットの値を高速にハッシュマップ中で検索することができるため、先の例の『172』の場合などには、一瞬で「ハッシュマップにキーが存在しない=比較すべきアイテムは存在しない=マッチしない」という結果を取得することができるようになります。
上記リストの例のように『192』のキーに対応するアイテムが複数(上記の例では3つ)存在する場合があるため、重複するアイテムが存在する場合には、ハッシュマップのバリューに格納するオブジェクトをStringではなくListで管理するようにします。Listに対するマッチングは先頭から順番に行う形としました。これは非効率的ですが、ネットマスク表記が『/8』や『/24』などさまざまなパターンが存在することを考えると、効率的な実装をするにはもう一工夫要りそうです。第一オクテットが同じアイテムが数千並ぶ可能性は低い(ネットマスク表記が可能なので、アイテム数は減る)ことが考えられるので、この部分はとりあえずこれでよしとすることにしています。
このインデックス化によって、IPアドレスリストのアイテムが数千ある場合のパフォーマンスは、最初のいちばん非効率だった実装に比べ、1000倍以上高速になりました。元のコードがいかにひどい実装だったかがよく分かる結果となっています。また、十分高速化されたため、結果をキャッシュに保持する方法も採らずに済むようになりました。
その7:並列化する
Scutumの従来の実装では、ある1つのHTTPセッションを処理するのは1つのスレッドでした。しかしリクエストやレスポンスのサイズが大きい場合には、シグネチャマッチングに時間を要する場合があります。そこで、例えば50個のシグネチャについて順番にマッチングを行うという従来の実装から、処理を10個のスレッドに分け、それぞれのスレッドで5個ずつシグネチャマッチングを行うような、並列化を考えました。このようにすることで、特にマルチコアのサーバではCPUリソースが非常に有効に活用され、例えば8コアの場合には1/8の時間でセッションが処理されることが期待できます。実装後にベンチマークテストを行った結果、期待どおりの性能が出ることがわかりました。
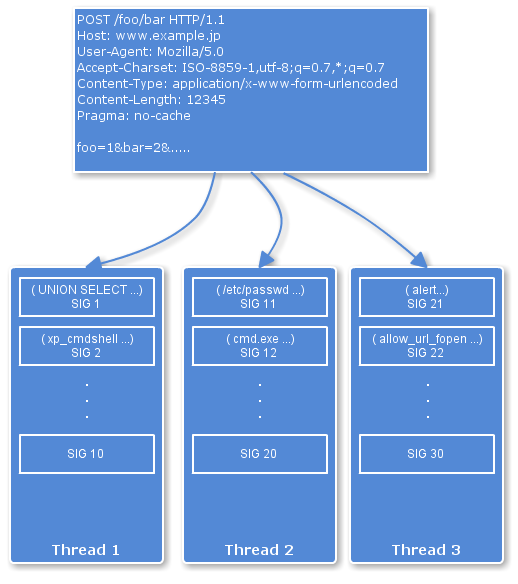
この方法のメリットはある1つの(大きなデータを含む)HTTPセッションについてのレイテンシが低下することですが、システム全体にそれなりに負荷が発生している場合には、システム全体のスループットに対しては特に変化は及ぼしません。現在は、大きなデータを含むHTTPセッションについてのみ並列化して処理するような運用を行っています。
この方法のデメリットは大きく2点あります。1点目はメモリの使用量が大きくなることです。そのため、メモリを潤沢に積んだサーバが必須となります。2点目は実装が複雑になるため、コードのメンテナンスコストが高くなることです。現時点ではテストを重ねた安定したコードとなっていますが、よりシンプルにし、メンテナンスがしやすい状態にしたいと考えているところです。最近ではJVM上でマルチスレッド処理を実装する方法としてActorパターンやSTMなど、より抽象化された方法が流行る兆しがありますが、Scutumではjava.util.concurrentの実装に近い、ある程度パターン化されたロックベースの独自実装を用いています。
おわりに
今回はJavaによって実装されているWAF、Scutumにおいて、過去に行ってきた様々なパフォーマンスチューニングテクニックを簡単にご紹介しました。上記7つのテクニックは、ほぼすべてパフォーマンスチューニングのテクニックとしてはいわゆる王道的なものなので、修羅場をくぐり抜けてきたプログラマの方には物足りない面もあったかと思います。今後もより高速なサービスを目指して精進したいと思います。ご意見・ご感想などありましたらお気軽に@kinyukaまでお知らせください。