技術者ブログ
クラウド型WAF「Scutum(スキュータム)」の開発者/エンジニアによるブログです。
金床“Kanatoko”をはじめとする株式会社ビットフォレストの技術チームが、“WAFを支える技術”をテーマに幅広く、不定期に更新中!
JavaのString生成方法がボトルネックになっていた話
はじめに
![]()
先日、私たちが開発しているクラウド型WAFサービス、Scutum(スキュータム)において、予想していなかった箇所の修正によってサーバの負荷が大幅に減るということがありました。原因はこのエントリのタイトルにもあるように、Stringクラスのインスタンスを生成する際の方法にありました。
Stringクラスのコンストラクタとcharset
Stringクラスにはいくつかのコンストラクタが用意されています。我々が使っていたのはString(byte[] bytes, String charsetName)です。2つめの引数で、"MS932"や"UTF-8"のような文字集合(以下charset)を明示的に指定するものです。
ScutumのようなWAF(Web Application Firewall)は通常のウェブアプリケーションとは異なり、起動している間にさまざまなcharsetを扱うことがあります。あるときは"MS932"でStringオブジェクトを生成し、次の瞬間には"UTF-8"で・・・のような処理が行われます。Javaは、基本的には1つのプロセス(アプリケーション)が、このように複数のcharsetを使っていくことを主として想定していません。
やけに深いスタックトレースが発見される
ある日、サーバの負荷が高い原因を調査するために、起動してから既にかなりの時間が経っているJavaプロセスに対して、jstackコマンドでスタックトレースを取得しました。その際、以下のような異常に深いスタックトレースが発見されました。
"Thread-49103" prio=10 tid=0x00007f58a01d6000 nid=0x8f243 runnable [0x00007f58523e0000] java.lang.Thread.State: RUNNABLE at java.util.zip.ZipFile.getEntry(Native Method) at java.util.zip.ZipFile.getEntry(ZipFile.java:306) - locked <0x00000005803a5180> (a java.util.jar.JarFile) at java.util.jar.JarFile.getEntry(JarFile.java:227) at java.util.jar.JarFile.getJarEntry(JarFile.java:210) at sun.misc.URLClassPath$JarLoader.getResource(URLClassPath.java:840) at sun.misc.URLClassPath$JarLoader.findResource(URLClassPath.java:818) at sun.misc.URLClassPath$1.next(URLClassPath.java:226) at sun.misc.URLClassPath$1.hasMoreElements(URLClassPath.java:236) at java.net.URLClassLoader$3$1.run(URLClassLoader.java:583) at java.net.URLClassLoader$3$1.run(URLClassLoader.java:581) at java.security.AccessController.doPrivileged(Native Method) at java.net.URLClassLoader$3.next(URLClassLoader.java:580) at java.net.URLClassLoader$3.hasMoreElements(URLClassLoader.java:605) at sun.misc.CompoundEnumeration.next(CompoundEnumeration.java:45) at sun.misc.CompoundEnumeration.hasMoreElements(CompoundEnumeration.java:54) at sun.misc.CompoundEnumeration.next(CompoundEnumeration.java:45) at sun.misc.CompoundEnumeration.hasMoreElements(CompoundEnumeration.java:54) at java.util.ServiceLoader$LazyIterator.hasNext(ServiceLoader.java:346) at java.util.ServiceLoader$1.hasNext(ServiceLoader.java:439) at java.nio.charset.Charset$1.getNext(Charset.java:355) at java.nio.charset.Charset$1.hasNext(Charset.java:370) at java.nio.charset.Charset$2.run(Charset.java:413) at java.nio.charset.Charset$2.run(Charset.java:411) at java.security.AccessController.doPrivileged(Native Method) at java.nio.charset.Charset.lookupViaProviders(Charset.java:410) at java.nio.charset.Charset.lookup2(Charset.java:480) at java.nio.charset.Charset.lookup(Charset.java:468) at java.nio.charset.Charset.isSupported(Charset.java:510) at java.lang.StringCoding.lookupCharset(StringCoding.java:99) at java.lang.StringCoding.decode(StringCoding.java:185) at java.lang.String.(上記はこれでも下の部分が省略されていて、実際にはアプリケーションのスタックがさらに続いています。)(String.java:416) (snip...)
ぱっと見た感じ、Stringの初期化において、イテレータ的なものによる多重ループの処理が行われています。しかも、何故かZipの処理(jarファイルの処理)までもが行われてしまっているようです。Stringクラスのインスタンスを生成するだけなのに、何故Zip処理が行われているのか、という点で猛烈な違和感を覚えました。
2つまでキャッシュされるcharset
上記スタックトレースにあるjava.nio.charset.Charset.lookupやlookup2のソースコードを読んでみたところ、Charsetクラスはstaticな2つのフィールドを使い、直近で使用された(lookupされた)Charsetクラスのインスタンスを2つまでキャッシュしていることがわかりました。
// Cache of the most-recently-returned charsets,
// along with the names that were used to find them
//
private static volatile Object[] cache1 = null; // "Level 1" cache
private static volatile Object[] cache2 = null; // "Level 2" cache
つまり、以下のように同じcharsetを使うコードが連続的に呼び出された場合には、あらかじめ生成されていて、既にキャッシュ済みのCharsetクラスのインスタンスが有効に利用されます。
new String( bytes1, "UTF-8" ); new String( bytes2, "UTF-8" ); new String( bytes3, "UTF-8" ); new String( bytes4, "UTF-8" ); ...
また、異なるcharsetが混在していても、以下のように2つまでなら、同じくキャッシュされたインスタンスが有効に利用されます。
new String( bytes1, "UTF-8" ); new String( bytes2, "UTF-8" ); new String( bytes3, "MS932" ); new String( bytes4, "UTF-8" ); ...
しかし、次のように異なるcharsetが3つ以上混在してしまっている場合、キャッシュは効きません。JavaランタイムはCharsetを探す処理をはじめからやり直してしまいます。
new String( bytes1, "UTF-8" ); new String( bytes2, "UTF-8" ); new String( bytes3, "MS932" ); new String( bytes4, "US-ASCII" ); new String( bytes4, "UTF-8" ); ...
JavaではCharsetをユーザが作成し、それを追加することができます。ScutumではUTF-8のバグを利用するディレクトリトラバーサルなどを検知するために、意図して古いUTF-8の実装を新しいJavaランタイムに追加しており、そのlookupには上記の深いスタックトレースにあるようなjarファイルの展開が必要とされてしまう、という形でした。
コメントにはっきり記述されているキャッシュ戦略
独自のcharsetを追加するかどうかに関わらず、3つ以上のcharsetを使い回すような用途は、Javaは想定していません。これは、Charsetクラスにある以下のコメントからわかります。
// We expect most programs to use one Charset repeatedly.
// We convey a hint to this effect to the VM by putting the
// level 1 cache miss code in a separate method.
1つのcharsetが繰り返し使用される場合に、より高速に処理が行われるようにlookupとlookup2を分けているように書かれていますが、これはJITコンパイラのためなのかと思われます(よくわかりません・・・)。いずれにせよ、2つまでキャッシュはされているので、3つ以上使う場合には極端にパフォーマンスに差が出ます。
対策は簡単
以上のように、Charsetクラスのキャッシュの挙動がはっきりしました。これに対してユーザ側ができる対策は、自分でCharsetクラスのインスタンスをキャッシュし、それをこちらのコンストラクタで使うことです。CharsetクラスのインスタンスはCharsetクラスのstaticメソッドであるforNameで取得できます。
目に見えて負荷が軽減した
さてこのような経緯でString生成のコンストラクタを変更し、自分たちのコード内でキャッシュしたCharsetクラスのインスタンスを使うようにしてみたところ、目に見えてサーバの負荷が軽減しました。
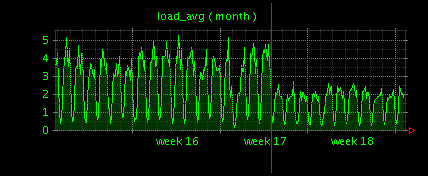
上図中の赤い線の部分が、独自のキャッシュ処理を開始した時点です。Load Averageの値が約半分に減りました。これまでScutumの負荷はシグネチャマッチングやベイジアンネットワークの処理だろうと勝手に思いこんでいたのですが、思わぬところにこんなボトルネックがあったのかと、正直かなり愕然としました。
秒間に数千以上も生成されるであろうStringクラスのインスタンスに対して、しょっちゅうZipの処理が走っていたのでは、重くなるのも当たり前です。問題を解決できてうれしい反面、数年以上の間、まったく気付くことができなかった事に対して悔いが残ります。
今回の問題は単純に同じHTTPリクエストを大量に送りつけるような負荷テストでは検出できない種類のもので、このように複雑なトラフィックを処理する本番環境のサーバではっきりと違いが出るものです。今後、テストの内容をより本番環境に近づけていく努力をするとともに、本番環境での検証についても、より積極的にやっていこうと決意しました。
おわりに
今回はJavaのStringクラスを生成する際のcharsetの扱いによって、パフォーマンスに大きく差が出る件についてまとめました。一般的なアプリケーションでは問題になることは殆ど無いと思われますが、WAFのように数種類のcharsetを同時に使っていくアプリケーションでは要注意です。本エントリについてのフィードバックはお気軽に@kinyukaまでお寄せください。